
就适用范围来说,正则表达式适用于文本内容,而通配符适用于文本名字。
正则表达式
- . 匹配任意字符
- \ 对字符转义
- | 选择操作(或)
- ^ 行起始字符
- $ 行终止
- ? 匹配0个或1个的量词
- *匹配0个或多个的量词
- +匹配一次或多次的量词 grep要转义\
- [ 字符组开始
- ] 字符组结束
- { 量词或代码的开始
- } 量词或代码的结束
- ( 分组开始
- ) 分组结束
- 反斜杠后面加大写字符为小写字符的取反,比如\b为单词边界,\B为非单词边界 \b 单词边界 grep里要加引号
- [\b] 退格符
- \cx 控制字符
- \d 数字
- \dxxx 字符的十进制
- \oxxx 字符的八进制
- \x xx 字符的十六进制
- \f 换页
- \r 回车
- \n 换行
- \s 空白符
- \t 水平制表符
- \w 单词字符
- \0 空字符
\\表示转义,只匹配一个斜杠。举例:\\.编译器解析后将会变成\.,将只匹配符号点.。
- (?d) Unix中的行
- (?i) 不区分大小写
- (?J) 允许重复的名字
- (?m) 多行
- (?s) 单行
- (?u) Unicode
- (?U) 默认最短匹配
- (?x) 忽略空格和注释
- (?-...) 撤销设置或关闭选项
- (\d)\d\1 第一个为分组,表示匹配第一个数字并将其捕获 \1表示对捕获的数字进行反向引用。
- 7+ 等同于 7{1,}
- 7* 等同于 7{0,}
7? 等同于 7{0,1}
懒惰量词:如果你想匹配最少而不是最多数目的字符,可以使用懒惰量词
- ?? 懒惰匹配0或1次 (其实就是0次)
- +? 懒惰匹配1或多次 (其实就是1次)
- *? 懒惰匹配0或1次 (其实就是0次)
- {n}? 懒惰匹配n次 (其实就是n次)
- {n,}? 懒惰匹配n或n次以上 (其实就是n次)
{m,n}? 懒惰匹配m到n次 (其实就是m次)
占有量词:匹配尽量多的。同懒惰量词相反。没有回溯,可能导致找不到匹配,因为一下次选定了所有输入,不再回头。
- ?+
- ++
- *+
- {n}+
- {n,}+
{m,n}+
前瞻: ancyent(?=marinere)
寻找每一行后面跟marinere的单词ancyent 反前瞻: ancyent(?!marinere)
寻找每一行前面跟marinere的单词ancyent
通配符
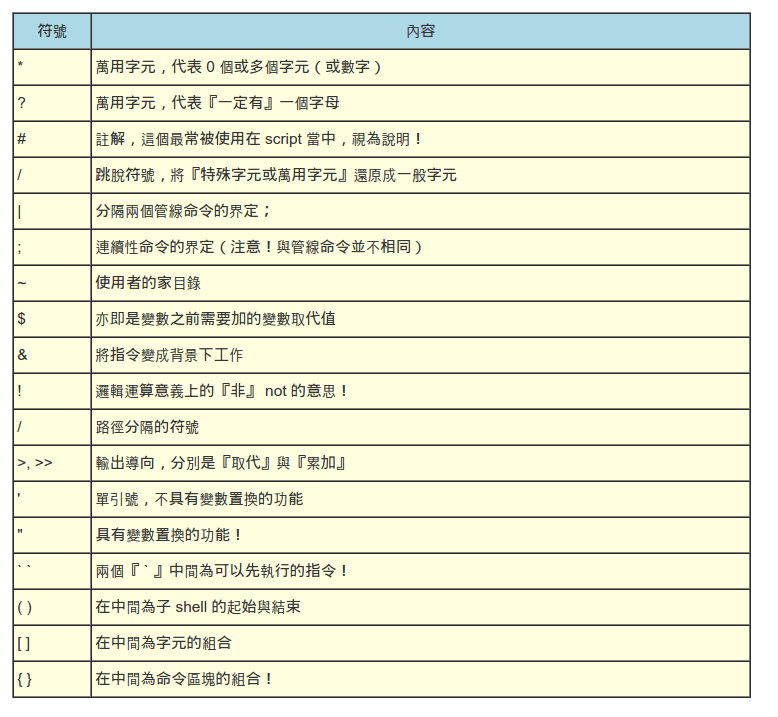


对于正则表达式和通配的关系这篇文章介绍这两者区别更为详细:正则表达式和通配符的区别
总的来说,就是grep采用正则表达式方式,搜索的是文件的内容。而egrep,awk,sed等采用的是通配符,搜索的是文件的名字。"*"号在正则中表示前面出现字符的0个或多个,在通配符中直接表示0个或多个字符;“?”号在正则中表示前面出现字符的0个或1个,在通配符中直接表示0个或1个字符。