
现在大部分分片系统的分片算法都是固定的,比如range分片、hash分片,或者range+hash分片。分片算法一旦设定通常没办法调整,一开始就需要trade-off各项因素,比如数据的workload,访问模型,负载均衡等。
该篇论文是可以动态调整分片分布。设置如何分片、如何复制、以及主从的放置策略。另外,还可以将事务访问的数据放到一个分片内来加速事务。它不是一个先验策略,而是基于workload学习到的cost model,来决定分片如何放置。
架构
引擎存储是行存结构,按照row-id进行按range分片,每条数据(行)属于一个partition,每个data site拥有一个或多个partition。每个partition是一个主从的集群,写主,然后异步复制给从节点,从节点数目可以不固定,可以为任意数目。客户端写入的时候,无需关注数据是位于哪个data site的哪个partition上面,这些都是由路由层(transaction router)决定的。基本架构图如下:
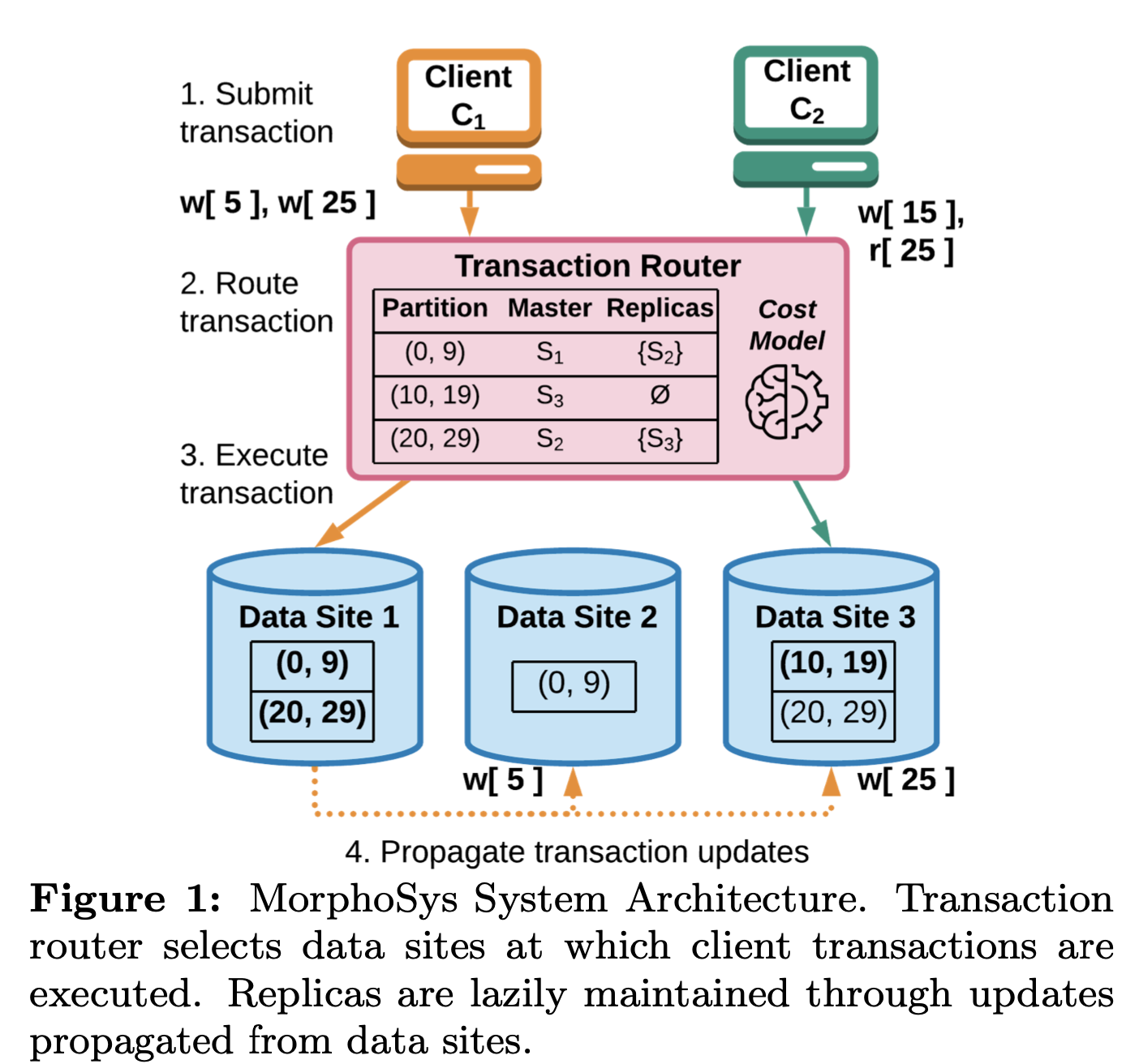
Client C1和C2同时提交了2个请求,C1发到DS1执行,C2发到DS3。图里面Transaction Router中的(20, 29)的Master应该是画错了,应该是S1。这样好处是事务都是单Site的事务,不涉及跨data site的事务,分布式事务可以优化为单机事务,少几次RPC。如果事务不满足条件,比如访问的数据不位于一个Site中,则会调整parition的副本(增加、删除),或者切换parititon的master节点,或者调整parition的粒度(数据分段区间),请求会等待调整结束后继续执行。这些操作叫做physical design change。这个对Transaction Router要求就比较高,需要动态感知workload并进行调整,保证后续请求及时响应。
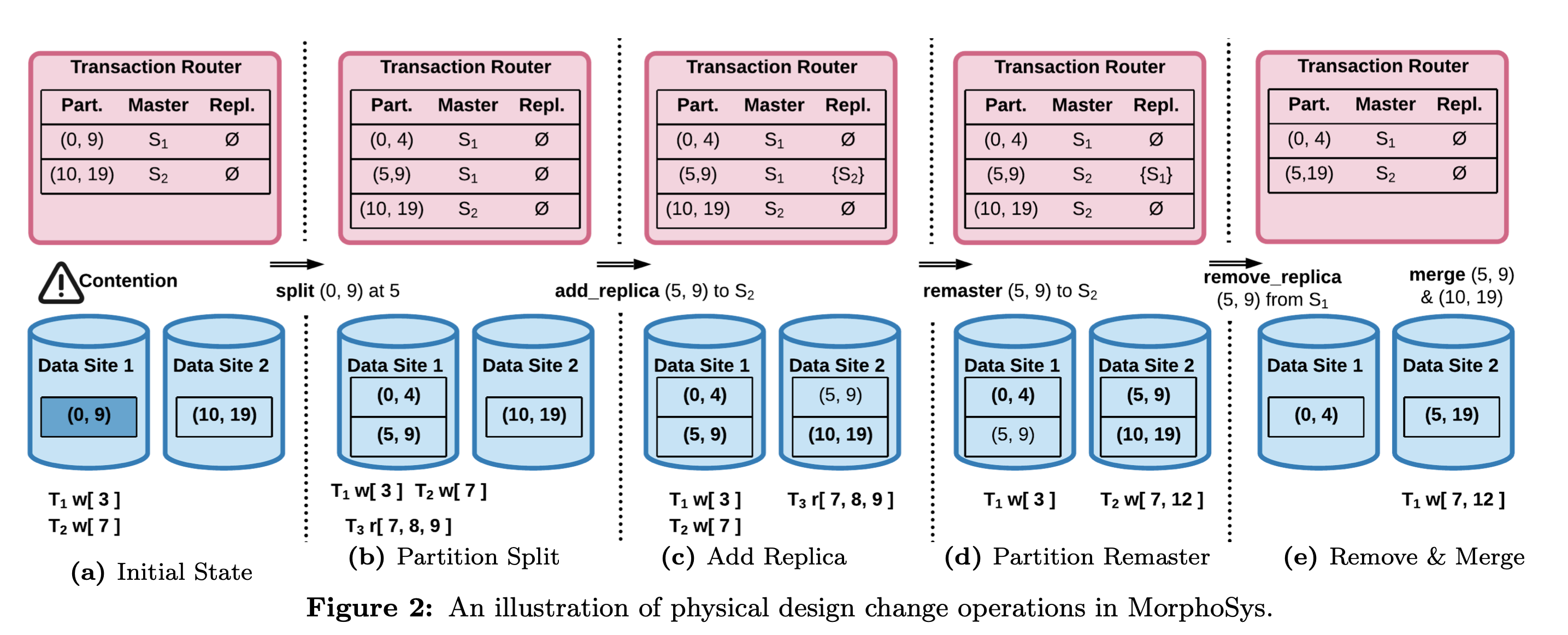
下图是另外一个数据访问的例子,涉及如何分裂、合并、切主、搬迁等,比较简单,一看就能理解。
事务模型
事务隔离级别选型SSSI(Strong-Session Snapshot Isolation),这是一个基于SI隔离级别的保证session内严格一致性的隔离级别,但是弱于Serializability。这个是论文Lazy database replication with snapshot isolation提出的,具体细节我也没有看。
MorphoSys是一个Partition-Based MVCC模型,每个partition独立维护MVCC多版本。写操作和physical design change操作都会加partition的锁,也就是说:一个partition同一时间只会有一个write操作。所以事务也不会因为冲突而回滚。只读事务和写事务可以并发。版本回收需要知道全局信息,知道当前版本已经没有被事务使用了就可以回收了。
主上的数据写入后会记录redo log,然后异步同步给从节点,从节点收到以后会当做一个客户端写入的事务一样走一遍事务的提交流程。
关键问题来了,如果客户端的读写的事务中的数据不在一个data site中存在怎么办?这时候就需要运维操作了,论文中叫做Physical Design Change Execution,有以下几种:
- 增加/删除partition replica。
- 分裂/合并partition。
- 切换partition replica的主节点:remaster。
- partition迁移。
也就是说,访问会先找一个尽量拥有全部数据的data site,如果有,那么皆大欢喜;如果没有,则会先让请求block,然后通过上面说的运维操作使得至少有一个data site满足条件,然后让请求继续。搞过分布式系统的同学都知道,这个操作非常重,所以需要有一套算法模型来保证尽量不涉及或者尽量少的进行这些运维操作,MorphoSys的算法:
- 根据之前的workload分析使得数据分片尽量满足需求。
- 根据cost model计算满足当前访问需求的运维操作的最小代价。
个人思考
一开始是抱着解决数据迁移痛点来读的这个论文,但是发现这个论文根本没有解决迁移的痛点,而且迁移操作更重。论文后半部分关于cost model没有阅读,就简单过了一下。这个论文也真的只能活在科研界了,就当前的工程实践发展来说,基本实现上不现实,如论再怎么优化Physical Design Change Execution,请求一旦不命中一个data site操作就太重了。但有一点可以值得借鉴,就是不同partition拥有不通的副本数目,当前大部分系统来说,分片的副本数目应该都是统一的,这对于有读热点的分片来说,可以动态调整。