1. 原子操作
内核提供了两组原子操作接口--一组针对整数进行操作,另一组针对单独的位进行操作。
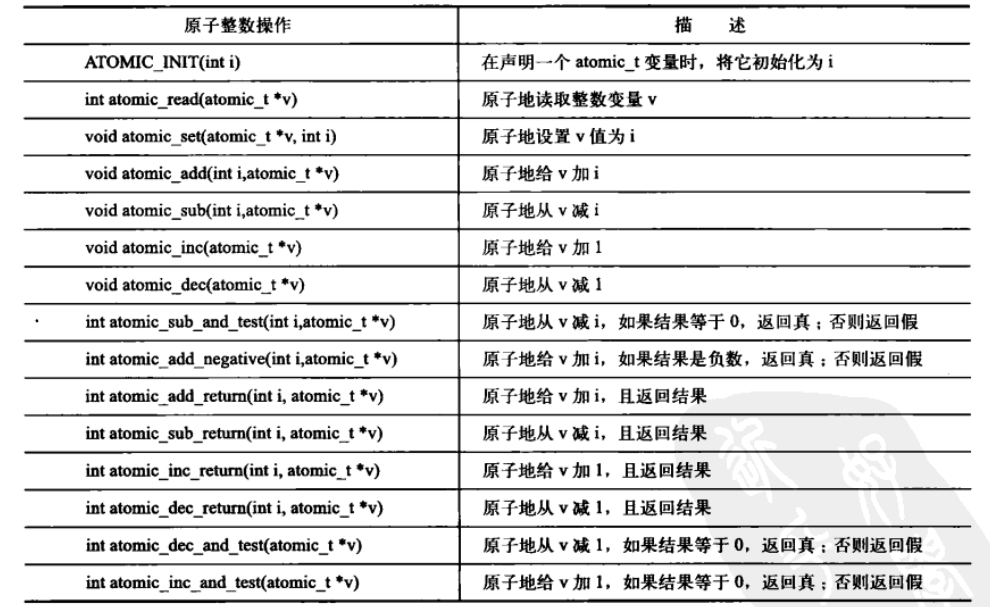
1.1 原子整数操作
针对整数的原子操作智能对atomic_t类型的数据进行处理。在这里之所以引入了一个特殊数据类型,而没有直接用C语言的int,主要处于以下原因:
- 让原子函数只接收atomic_t类型的操作数,可以确保原子操作只与这种特殊类型数据一起使用。同时,也保证了该类型的数据不会被传递给任何非原子函数。
- 使用atomic_t类型确保编译器不对相应的值进行访问优化--这点使得原子操作最终接收到正确的内存地址,而不是别名。
- 在不同体系结构上实现原子操作的时候,使用atomic_t可以屏蔽其间的差异。
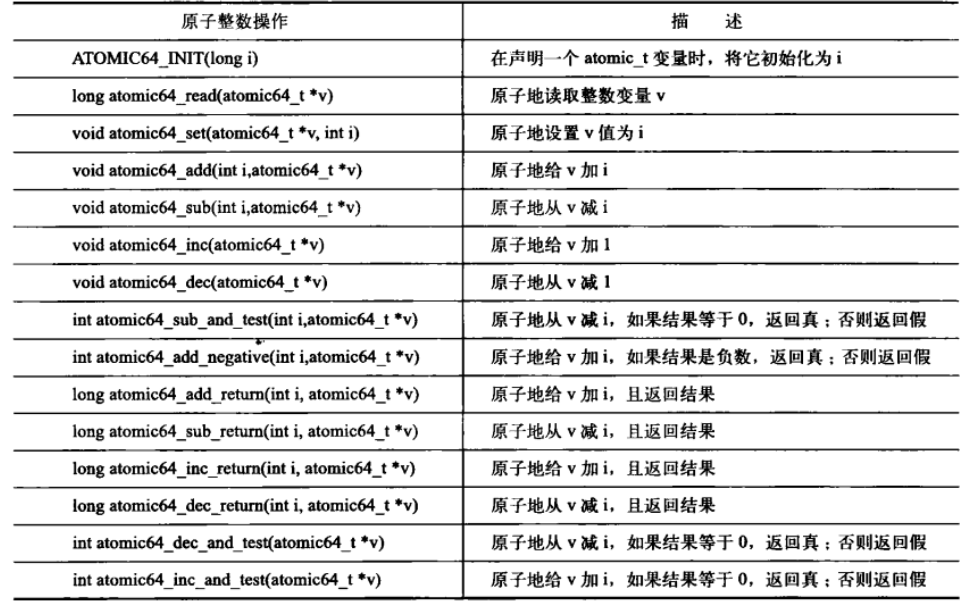
atomic_t是32位数,后来引入了64位的atomic64_t。下图是原子整数操作函数表:
1.2 原子位操作
另人感到奇怪的是位操作函数是对普通的内存地址进行操作的。
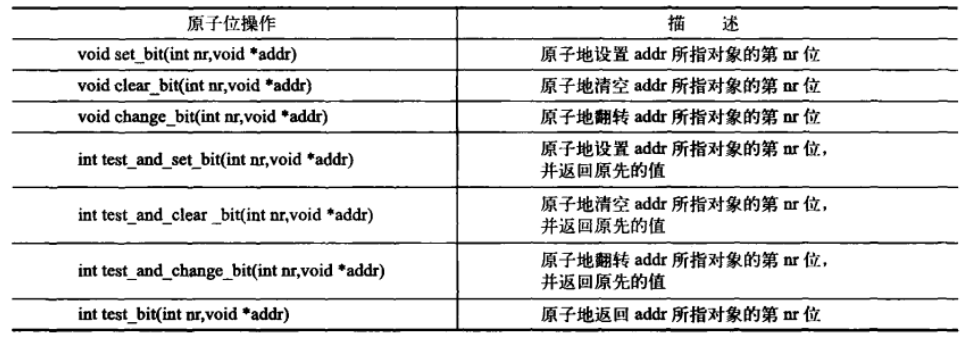
为了方便起见,内核还提供了一组与上述操作对应的非原子位函数。非原子位函数与原子位函数的操作完全相同,但是,前者不保证原子性,且其名字前面多两个下划线。
举例:假定给出两个原子位操作:先对某为置位,然后清0。如果没有原子操作,那么,这一位可能的确清0了,但是也可能根本没有置位。置位操作可能与清除操作同时发生,但没有成功。清除操作可能成功了,这一位如愿呈现为清0。但是,有了原子操作,置位会真正发生 ,可能有那么一刻,读操作显示所置的位,然后清除操作才执行,该位变为0了。
2. 自旋锁
自旋锁是linux内核中最常见的锁。自旋锁最多只能被一个可执行线程持有。如果一个执行线程试图获得一个被已经持有的自旋锁,那么该线程就会一直轮询等待可用。要是锁未被征用,请求锁的执行线程便能立刻得到它,继续执行。
自旋锁的初衷就是:在短时期内进行轻量级加锁。其实还可以采取另外的方式来处理对锁的争用:让请求线程睡眠,直到锁重新可用时再唤醒它。这样处理器就不必循环等待,可以去执行其他代码。这样也会带来一定的开销--这里有两次明显的上下文切换,被阻塞的线程要换出和换入,与实现自旋锁的少数几行代码相比,上下文切换当然有更多的代码。因此,持有自旋锁的时间最好小于完成两次上下文切换的消耗。
2.1 自旋锁方法
基本使用如下:
DEFINE_SPINLOCAL(mr_lock);
spin_lock(&mr_lock);
/*临界区...*/
spin_unlock(&mr_lock);
如果禁止内核抢占,那么在编译时自旋锁会被完全剔除内核。
linux中,内核实现的自旋锁是不可递归的,这点不同于自旋锁在其他OS中的实现。
自旋锁可以使用在中断处理程序中。在中断处理程序中使用自旋锁时,一定要在获取锁之前,首先禁止本地中断(在当前处理器上的中断请求),否则,中断处理程序就会打断正在持有锁的内核代码,有可能会试图去争用这个已经被持有的自旋锁。这样依赖,中断处理程序就会自旋,等待该锁重新可用,但是锁的持有者在这个中断处理程序执行完毕前不可能运行。这就是双重请求死锁。注意,需要关闭的只是当前处理器上的中断。
spin_lock_irqsave()保存中断的当前状态,并禁止本地中断,然后再去获得指定的锁。反过来spin_unlock_irqrestore()对指定的锁解锁,然后让中断恢复到加锁前的状态。
如果能确定中断在加锁前是激活的,那就不需要在解锁后回复中段以前的状态,这时候可以无条件的在解锁时激活中断。使用spin_lock_irq()和spin_unlock_irq()会更好一些。
下图给出了标准的自旋锁操作的完整列表。
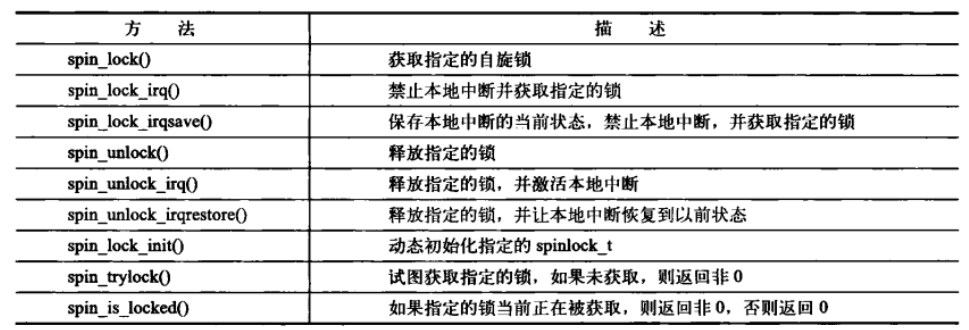
2.2 自旋锁和下半部
由于下半部可以抢占进程上下文中的代码,所以当下半部和进程上下文共享数据时,必须对进程上下文中的共享数据进行保护,所以需要加锁的同时还要禁止下半部执行。同样,由于中断处理程序可以抢占下半部,所以如果中断处理程序和下半部共享数据,那么就必须在获取恰当的锁的同时还要禁止中断。
回忆一下,同类的tasklet不可能同时运行,所以对于同类tasklet中的共享数据不需要保护。但是当数据被两个不同种类的tasklet共享时,就需要在访问下半部中的数据前先获得一个普通的自旋锁。这里不需要禁止下半部,因为在同一个处理器上绝不会有tasklet相互抢占的情况。
对于软中断,无论是否同种类型,如果数据被软中断共享,那么它必须得到锁的保护。这是因为,即使是同种类型的两个软中断也可以同时运行在一个系统的多个处理器上。但是,同一处理器上的一个软中断绝不会抢占另一个软中断,因此,根本没有必要禁止下半部。
3. 读-写自旋锁
当对于某个数据结构的操作可以被划分为读/写或消费者/生产者两种类别时,类似读/写锁这样的机制就很有帮助了。为此,linux提供了专门的读写自旋锁。一个或多个读任务可以并发的持有读写锁;相反,用于写的锁最多只能被一个写任务持有,而且此时不能有并发的读操作。
读者代码:
read_lock(&mr_rwlock);
/*临界区(只读)...*/
read_unlock(&mr_rwlock);
写者代码:
write_lock(&mr_rwlock);
/*临界区(只写)...*/
write_unlock(&mr_rwlock);
执行下列代码将出现问题:
read_lock(&mr_rwlock);
write_lock(&mr_rwlock);
因为写锁会不断自旋,等待所有的读者释放锁,其中也包括它自己。所以当确实需要写操作时,要在一开始就请求写锁。如果写和读不能清晰地分开的话,使用一般的自旋锁就可以了,不要使用读写锁。
多个读者可以安全的获得同一个读锁,事实上,即使一个线程递归地获得同一个读锁也是安全的。这个特性使得读写自旋锁成为一种有用并且常用的优化手段。
下表为读-写自旋锁方法列表:
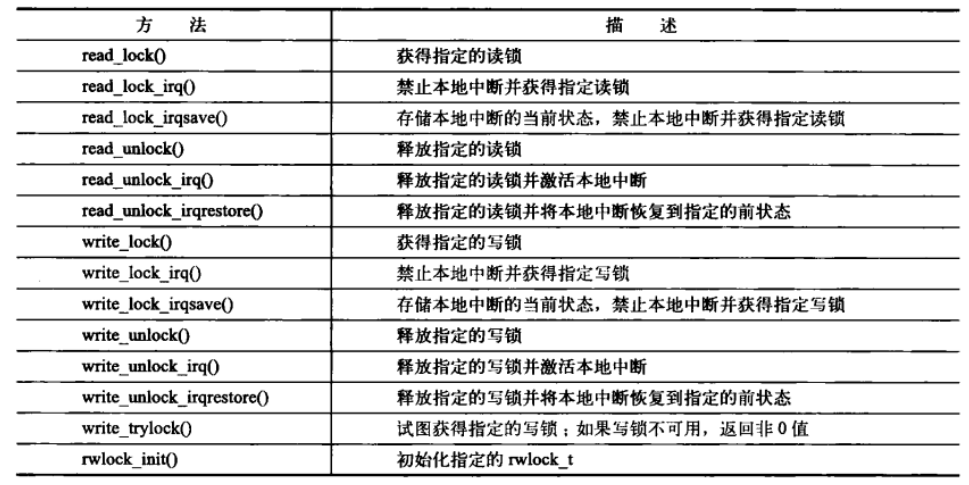
在使用linux读-写自旋锁时,最后要考虑的一点是这种锁机制照顾读比照度写多一点。当读锁被持有时,写操作为了互斥访问只能等待,但是,读者却可以继续成功地占用锁。
trylock与普通lock的区别在于:trylock在资源不可用时返回,而普通lock则进入睡眠等待资源可用。
4. 信号量
Linux中的信号量是一种睡眠锁。如果有一个任务试图获得一个不可用的信号量时,信号量会将其推进到一个等待队列,然后让其睡眠。这是处理器能重获自由,从而去执行其他代码。当持有的信号量可用后,处于等待队列中的那个任务将被唤醒,并获得该信号量。
信号量比自旋锁有更大的开销。另外,信号量不同于自旋锁,它不会禁止内核抢占,所以持有信号量的代码可以被抢占。关于信号量的结论如下:
- 由于争用信号量的进程在等待锁重新编为可用时会睡眠,所以信号量适用于锁会被长时间持有的情况。
- 相反,锁被段时间占有时,由于开销问题,信号量不合适。
- 由于执行线程在锁被争用时会睡眠,所以只能在进程上下文中才能获取信号量锁,因为中断上下文是不能进行调度的。
- 持有信号量可以睡眠。
- 占有信号量同时不能占有自旋锁。因为在等待信号量时可能会睡眠,而在持有自旋锁时是不允许睡眠的。
信号量可以同时允许任意数量的锁持有者,而自旋锁在任意时候最多有一个。使用者数量为1时为互斥信号量,大于1时为技术信号量。
内核分别用down()和up()来获取和释放信号量。
struct semaphore类型表示信号量。
如果信号量不可用,它将把调用进程设置为TASK_INTERRUPTIBLE状态--进入睡眠,这种状态意味着任务可以被信号唤醒。
下表为信号量方法列表。
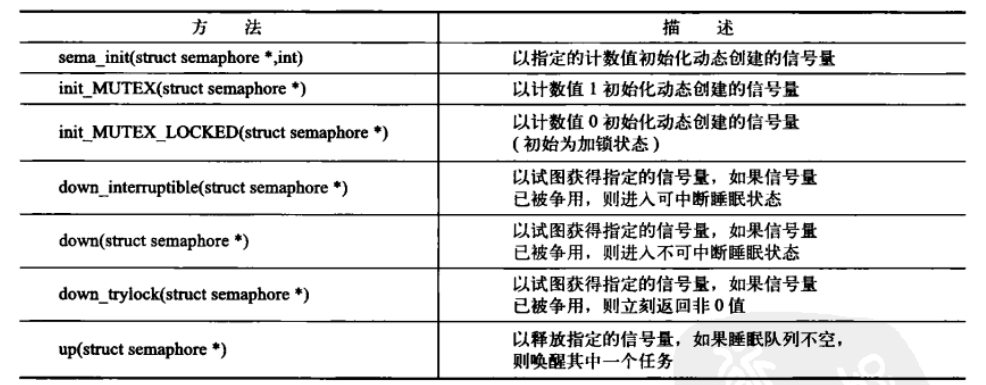
5. 读-写信号量
与自旋锁一样,信号量也区分读-写访问的可能。与读-写自旋锁和普通自旋锁之间的关系差不多,读写信号量也要比普通信号量更具优势。
读写机制使用是有条件的,只有在代码可以自然界定出读-写时才有价值。
6. 互斥体(mutex)
互斥体与互斥信号量类似。下图是其方法列表:

使用mutex相对而言更加严格,更定向:
- 任何时刻只有一个任务可以持有mutex,也就是使用计数永远是1.
- 给mutex上锁者必须负责给其再解锁--不能在一个上下文中锁定一个mutex而在另一个上下文中给它解锁。这个限制使得mutex不适合内核同用户空间复杂的同步场景。最常使用的方式是:在同一个上下文中上锁和解锁。
- 递归上锁和解锁是不允许的。不能递归持有同一个锁,同样不能解锁已经被解开的mutex。
- 当持有一个mutex时,进程不可以退出。
- mutex不能在中断或者下半部中使用,即使使用mutex_trylock()也不行。
- mutex只能通过官方API管理
6.1 信号量和mutex
两者很相近。它们的标准使用方式都有简单的规范:除非mutex的某个约束妨碍你使用,否则相比信号量要优先使用mutex。当你写新代码时,只有碰到特殊场合(一般是很底层代码)才会需要使用信号量。
6.2 自旋锁和mutex
在中断上下文中只能使用自旋锁,而在任务睡眠时只能使用mutex。下表回顾了各种锁的需求情况:

7. 完成变量
如果在内核中一个任务需要发出信号通知另一个任务发生了某个特定事件,利用完成变量(completion variable)是使得两个任务得以同步的简单方法。这听起来很像一个信号量,事实的确如此。完成变量仅仅提供了代替信号量的一个简单解决办法。例如,当子进程执行或退出时,vfork()系统调用使用完成变量唤醒父进程。

8. BKL:大内核锁
它是一个全局自旋锁,使用它主要是为了方便实现从linux最初的SMP过渡到细粒度加锁机制。它的特征:
- 持有BKL的任务仍然可以睡眠。因为当任务无法被调度时,所加锁会自动被丢弃;当任务被调度时,锁又会被重新获得。
- BKL是递归锁。
- BKL只用于进程上下文中。
- 新的用户不允许使用BKL。
在内核中不鼓励使用BKL。事实上,新代码不再使用BKL,但是这种锁仍然在部分内核代码中得到沿用。
多数情况下,BKL更像是保护代码而不是保护数据。

9. 顺序锁
也称seq锁,这种锁提供了一种很简单的机制,用于读写共享数据。它对写者更有利。只要没有其他写者,写锁总是能够被成功获得。读者不会影响写锁,这点和读写自旋锁以及信号量一致。另外,挂起的写者会不断的使读操作循环,直到不再有任何写者持有锁为止。
适用范围:
- 数据存在狠毒读者
2, 写者很少
3, 虽然写者很少,但是希望写优先于读,而不允许读者让写者饥饿。 - 数据很简单,如简单结构。
使用seq锁中最有说服力的是jiffies。该变量存储了Linux机器启动到当前的时间。
10. 禁止抢占
由于内核是抢占性的,内核中的进程在任何时刻都可能停下来以便让另一个具有更高优先权的进程运行。这意味着一个任务与被抢占的任务可能会在同一个临界区内运行。为了避免这种情况,内核抢占代码使用自旋锁作为非抢占区的标记。如果一个自旋锁被持有,内核便不能进行抢占。因为内核抢占和SMP面对相同的并发问题,并且内核已经是SMP安全的,所以,这种简单的变化使得内核也是抢占安全的。
实际中,某些情况并不需要自旋锁,但是仍然需要关闭内核抢占。最频繁出现的情况就是每个处理器上的数据。
可以通过preempt_disable()禁止内核抢占。这是一个可以嵌套调用的函数,可以调用任意次。每次调用都必须有一个相应的preempt_enable()调用。当最后一个preempt_enable()被调用后,内核抢占才重新启动。以下是内核抢占的相关函数。

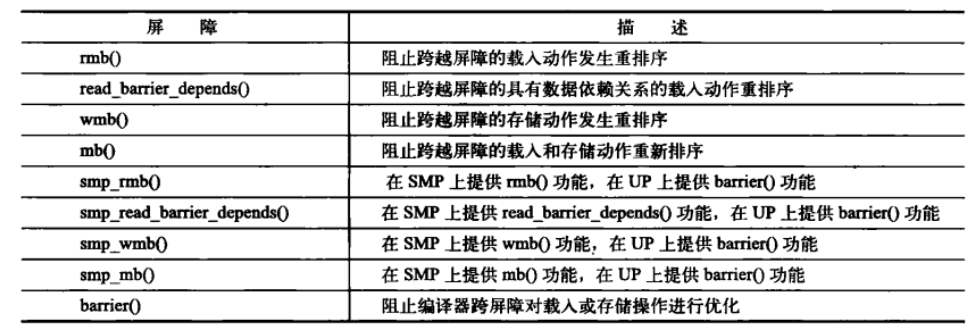
11. 顺序和屏障
当处理多处理器之间或硬件设备之间的同步问题时,有时需要在程序代码中以指定的顺序发出读内存和写内存的指令。在和硬件交互时,时常需要确保一个给定的读操作发生在其他读或写之前。另外,在多处理器上,可能需要按写数据的顺序读数据。而这些都有可能被编译器优化,重新排序。可以使用屏障(barriers)确保指令顺序。如下表所示。