
最近调研了一些关于数据中心网络监控的论文和解决方案,主要关于丢包和延时的定位排查,现在telemetry的技术比较火热,写点东西小结一下,越来越懒得写博客了,写的不是很详细,特别是后面几篇,也可能有理解不到位的地方,欢迎指正。
1. Pingmesh
Pingmesh是微软在2015年提出的,其架构模式在那之前已经在微软的数据中心运行了超过4年,采用商用交换机,每天收集10TB的延迟数据。它能够解决以下三个问题:
- 定位业务的延迟是否因为网络
- 提供并且跟踪当前网络服务水平(service level agreement )
- 自动排除障碍
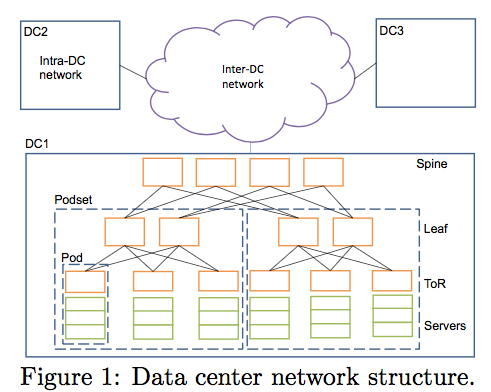
微软数据中心采用CLOS架构,如下图所示。拥有的规模如下:服务器规模在10万级别,交换机规模为万,服务器上联万兆。论文中阐述的一些统计和架构如下:时延统计采用端到端,中控系统为微软自己的Autopilot系统,采用Cosmos数据分布式系统进行数据存储。
1.1 agent
Pingmesh的agent安装在所有服务器内部,由于安装在服务器内部,需要控制一下由于agent给服务器带来的压力,CPU、内存等,此处不具体讨论。agent可以从控制器下载pinglist,pinglist是存储于服务器内,告诉每台服务器应该ping哪些机器,根据这个,每台服务器都可以发ping包了。当然,此处的ping包不是icmp的ping包,在该论文中,为了定位延迟与丢包,最佳策略是采用与丢的包同样类型的包,由于微软DC内,TCP和HTTP报文比较多,所以采用该类型的ping包代替ICMP,UDP,具体如何构造TCP ping包查看一下论文吧。
在ping的过程中,考虑到ECMP的将会把报文做不同的端口进行分发,所以每次ping都采用新的连接和新的端口,这是出于五元组哈希考虑,尽可能探测到每条链路的情况,另外还能防止拥塞。服务器与控制器保活3s,对端断开连接后,从控制器侧获悉对方状态,移除相应的ping peer。论文中的探测周期大于10s。agent本地对数据进行缓存,缓冲区大小由控制器配置,所谓的数据是ping的结果,延迟、可达等。agent定期将数据上传到日志系统,若传递失败则直接丢弃。对这个实验结果,论文给出的服务器使用率如下:2500台服务器互相ping的情况下,CPU使用率0.25%,内存在45MB。
1.2 pinglist产生算法
暴力
原始想法是暴力解:n个服务器,每个服务器ping其余n-1个服务器,那么复杂度在O(n^2)级别,负荷太大。
改进
论文提出的改进方式如下:
- pod内。以服务器为单位发起ping。
- DC内。以TOR为单位,一个TOR下选取一台或者多台服务器发起ping。
- DC间:以DC为单位,一个DC内选取多台服务器发起ping。
下面解释一下,DC内是如何选取TOR下的服务器的。对每个TOR对TOR-pair (TORx, TORy),让每个TOR下面编号为i的服务器ping另外一个TOR下面编号同为i的服务器。复杂度由O(n^2)降到O(n^2/k),k为一个TOR下连服务器的个数。
对于pod内比较简单,没啥需要特别解释的;对于DC间,论文说的比较模糊:每个podset下选取几台服务器发起ping。
1.3 controller
控制器主要实现以下几个功能:
- 维持全局拓扑
- 产生pinglist算法
- 南向提供rest接口供agent进行拉取pinglist
- 南向提供vip供负载均衡:controller不止一台
1.4 数据存储和分析DSA
agent定期将数据上传到Cosmos,为了抗压力,Cosmos同样做负载均衡。agent将数据上传到Cosmos之前会先进行本地统计,主要包括丢包率,以及延迟统计。在Cosmos侧,定期执行3种SCOPE任务(SCOPE为基于Cosmos的脚本语言),分别为10分钟,1小时和1天。10分钟任务主要为一些实时任务,比如收集延时,丢包数据进行告警、图表(网络连通)绘制;1小时和1天的任务为非实时性任务,主要进行服务质量探测,黑洞探测和丢包探测。另外为了减少响应时间,Autopilot平台还提供了5分钟任务,主要用于收集一些丢包的计数。(我的理解:这个好像和10分钟任务有点重复)
以上结果都将存储于db,方便后续做可视化以及报警等。
另外,不止对agent数据处理,还有watchdog提供对控制器运行状况的监控。在论文中分析,每天收集约24TB的数据(不知道具体服务器量级)。
那么,具体如何分析丢包和延迟?请看下面2个图。
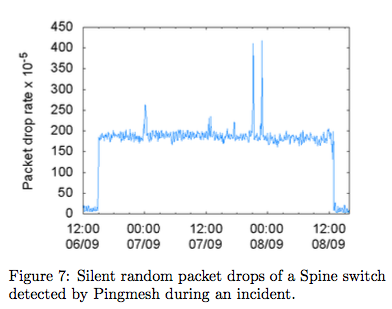
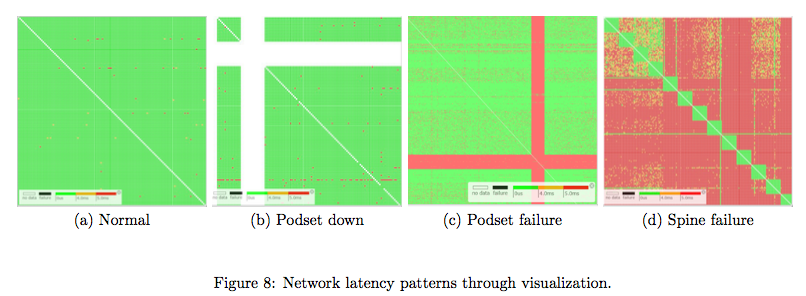
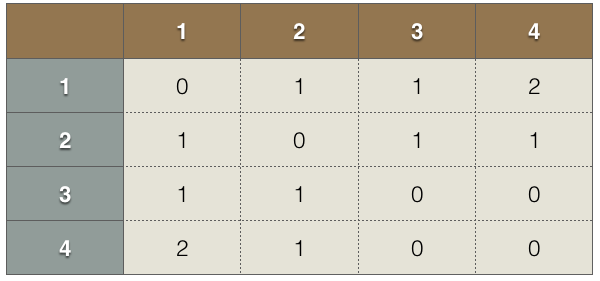
答案就是可视化分析,通过第1个图可以知道什么时候网络出现大延迟了,第二图是可视化矩阵(行列分别是服务器),可以表示大概什么位置出问题了,然后再用traceroute具体定位出问题的链路/交换机。为了清除起见,我画了下面这个表解释一下可视化矩阵,其中0表示不可达,1表示正常,2表示延迟,那么这个表说明了1和4服务器有延迟,3和4之间不可达。
1.5 我的理解
pingmesh优点是能够解决延迟和丢包问题,缺点是量级有点大,而且需要在服务器内进行部署,不太方便操作。
2. Everflow
这个同样是微软的论文,于2015年发表在SIGCOMM,也是采用商用交换机,其针对现有网络监控存在的痛点进行解决:
- 端到端的时延无法定位到具体链路
- 即使交换机的丢包计数正常,也有可能丢包
- TCP到VIP的连接可能出现超时,但是traceroute探测会被负载均衡
- ECMP路径hash不均但是很难跟踪:到底是流大小的问题还是哈希算法等问题
其主要思想是对每个包在每一跳交换机都进行匹配和镜像,然后进行独立的分析。其实也不是『每个』包,后续会有介绍。
2.1 改方案设计面临的挑战
第一是容量问题。目前数据中心的服务器可能超过10万台级别,带宽很容易超过100Tbps,按照CLOS架构5跳,平均吧大小1000byte进行计算,把镜像的包截取到最小的64byte,那么带宽也需要32Tbps。假设服务器处理线速在10Gbps,那么也需要超过3200台服务器,而且还需要处理同一个包的不同跳记录存储到同一个服务器。
第二是之前被动定位丢包策略的缺点。被动跟踪丢包难以定位是短期丢包还是长期丢包;场地的话难以确认是随机丢包还是因为黑洞丢的包;而且traceroute,ping等策略计算的时延不准确。
2.2 设计的关键思想
2.2.1 镜像报文
正如上文所说,设计的关键思想是在镜像报文,在商用交换机上设置特定匹配规则,匹配后执行对应的策略(比如将包发往收集端进行分析)。由于处理所有包的代价太过昂贵,对每条流都选取几个报文进行处理,至于如何选取特定报文,抱歉我没看懂。
另外,everflow还提供灵活跟踪策略:可以预先指定跟踪包头内打上debug标记的报文,对所有该种报文都进行监控镜像。另外还提供对网络协议的跟踪,比如BGP、PFC和RDMA等。
2.2.2 存储
由于正常报文和非正常报文比例悬殊(正常报文比较多),不能一视同仁,所以对于正常报文,进行聚合存储;对于非正常报文,存储详细信息。
2.2.3 报文重组
因为每个交换机都会产生很多的收集报文,而跟踪一个trace(一个报文进过的所有交换机路径)有比较大的分析的意义,所以这个很有必要。
2.2.3 报文探测
有时候需要定期或者事后对网络进行探测,发送探测报文有助于发现和定位问题。
2.3 基本架构
下图是everflow的架构图。下面将分别进行介绍。其中,控制器负责全局拓扑,北向提供API给用户使用。初始化的时候,下发策略到交换机提供对报文的匹配;控制器还可以对Analyzer进行配置,Analyzer是报文分析的地方,分析的结果存入Storage。另外,还有Reshuffler提供负载,这是因为报文收集的压力较大,所以需要多台Analyzer进行负载,Reshuffler是负载器,保证同一个trace的报文会被收集到同一台服务器上。控制器还可以主动给交换机发送探测报文,还可以给固定服务器下联端口打标监控。
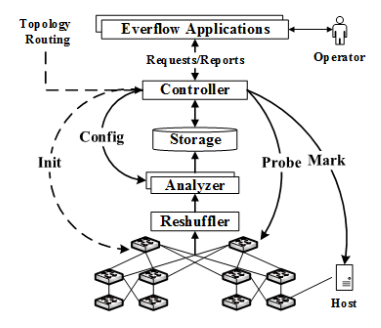
2.3.1 Analyzers
Analyzers主要对报文信息进行收集然后分析,其主要分析两个指标:Packet trace和Counter。
2.3.1.1 packet trace
一个trace标识一个包经过的所有交换机的路径,其根据5元组和IPID进行定位。经过每跳交换机都需要收集以下信息:交换机IP,时间戳,TTL,源MAC和DSCP/ECN。当然,以上这些信息的收集需要交换机芯片的支持,这个应该是微软和厂商定制芯片的结果。根据以上这些信息,可以定位丢包时延。在后面我会具体介绍如何定位。
因为每个报文每跳交换机的信息都会被收集,所以什么时候判断结束?论文给出的方案是卡1秒钟的阈值,超过1秒没有新报文达到,就认定该trace结束。另外,为了处理隧道报文,跟踪最内层报文的信息进行定位。
Analyzer还会定期聚合数据进行统计。由于有抽样的概念存在,具体如何利用聚合的数据进行分析不得而知。
2.3.1.1 counter
有三种类型的counter: 链路负载计数、延迟计数和镜像报文丢包计数。不做具体介绍,有需要请查看论文。
2.3.2 Controller
控制器控制全网交换机,提供一些API提供对丢包延迟的定位:查询固定报文的packet trace;安装细粒度的负载计数;触发探测报文;对固定流量包头打标识方便监测。
论文给出了几个在控制器之上APP的例子:
- Latency profiler。 提供延迟的定位。首先,在端到端探测中,通过在TCP SYN包中加debug bit,通过跟踪这些报问知道网络 扑状况,然后通过guided probes探测每跳延迟进行分析。
- Packet drop debugger。丢包定位。这个比较好搞,因为每跳信息都收集了,结合拓扑就知道丢在哪一跳了。比如正常应该是hosta->switch1->switch2->switch3->hostb。结果发现收集上来的信息只有switch1->switch2,那么证明在switch2->switch3之间发生了丢包。
- Loop debugger。loop定位。只要判断任何一个结点出现超过1次则可证明出现loop。
- ECMP profiler。分析端口负载可得。
- RoCRv2-based RDMA debugger。
2.4 如何镜像报文
利用GRE隧道,内层报文不变,外层源ip为交换机ip,目的ip是reshuffler的ip。
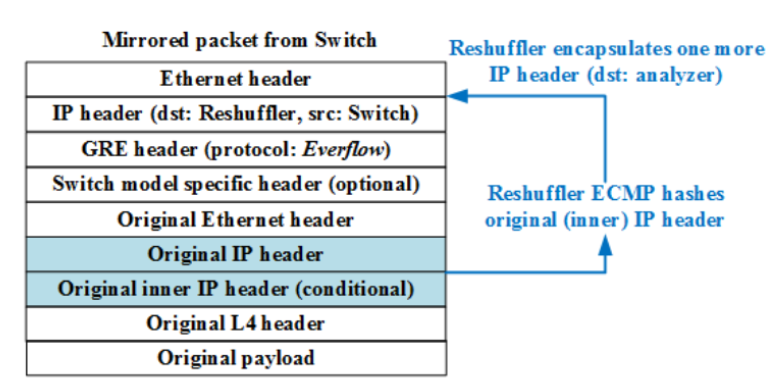
2.5 如何探测任意链路
论文给出的探测方式有TCP,UDP,ICMP等。那么如何把一个报文发给交换机S?答案是在外层封上隧道,目的ip是交换机S的环回地址,当报文到达S,S发现其目的地址为本交换机的环回地址后,剥离第一层报头。根据以上过程,可以探测任意组合的链路,比如探测S1->S2->S1。只要进行多次封装,最外层包头目的地址为S1的环回地址,第二层为S2,最内层是S1。
特殊处理:为了防止探测报文干扰正常业务,对其校验和设置为错误,所以最后一跳交换机不会发送给服务器。
2.6 Reshuffler
reshuffler根据报文内层5元组进行哈希,其对外提供一个VIP,报文到达后,封上一个隧道,目的DIP地址为不同的Analyzer。另外,论文从带宽压力考虑,用交换机代替服务器当做Reshuffler。
2.7 实验数据
10K交换机,250K链路,100Tbps流量情况下,用了63台Analyzer,1台reshuffler。其中Analyzer的带宽为380Gps,CPU为300M pps,存储为4.75MB/s。
2.8 我的理解
需要交换机芯片的支持,压力跟采样率相关。
3. NetSight
Netsight我不做具体介绍,其思想跟Everflow比较相似,也是收集每个报文每一跳交换机的信息,然后压缩扔给日志系统进行分析,只不过采用的是openflow,比较灵活。
4.In-band network Telemetry(INT)
这个是个协议,由Barefoot, Arista, Dell, Intel和VMware共同推出。我不做特别具体的介绍,就介绍一下大概设计思想。Facebook根据这个协议和相应厂商的交换机设计了一套系统。
INT的思想是在第一跳交换机收到相应报文,对其进行封装特定报文,然后扔给下一跳,直到最后一跳交换机,每一跳交换机都会收集相应的信息,封在报文里面。最后,在最后一跳交换机剥离报文里面收集到的信息,然后把原始报文扔给服务器,收集到的交换机信息扔给监控端处理。这样即不影响正常业务转发,又能收集到经过交换机的信息,在黑盒不知道网络拓扑的情况下还能探测出网络拓扑。那需要收集哪些信息,初步协议给定的有:交换机ID,入端口信息,入端口时间戳,出端口ID,出端口时间戳,出端口链路利用率,buffer信息。
个人理解这种好处肯定是能定位丢包和延迟,但是同样需要交换机硬件的支持。
FB根据这个搞了一套系统,表明未来会进行开源。
5.ATPG
这篇论文是在pingmesh上做优化,其根据推导算出大概需要最少多少个报文能探测全网的链路和交换机ACL。其中4000个报文能够覆盖斯坦福的校园网,54个报文能够探测到所有链路。
6.Planck
这篇论文是做端口流量镜像,然后进行分析。应该采用的是Openflow比较灵活,而且可以不用上CPU,交换机压力少,然后论文根据一定的算法计算丢包和延迟。我不做具体介绍。
7.我的想法
首先是Openflow策略,因为Openflow比较灵活,能控制的东西很多,所以比较方便,丢包延时根据netsight思想可以做的不错。
但目前来说,大部分公司的数据中心都没有推开Openflow,所以如果是商用交换机,而芯片层无法提供想要的需要,可能做的比较吃力,粒度自然就比较细,可以采用类似pingmesh的方案。
但如果是自己研发交换机软件或者和交换机厂商有合作,能提供给定的需求,那么Everflow/INT这种思想能够进行细粒度的定位。反正我个人是比较喜欢这种方案的。
说明
装载请注明出处:http://vinllen.com/shu-ju-zhong-xin-wang-luo-jian-kong-xiao-jie
参考
以上所有论文