
本文将主要首先聊一聊数据库同步和迁移两个话题,之后将会围绕这2个话题介绍一下阿里云最近开源的基于MongoDB和Redis的数据同步&迁移工具MongoShake和RedisShake,最后介绍一些用户的使用案例。
1. 同步
现在大部分数据都支持集群版的数据,也就是说一个逻辑单元中有多个db节点,不同节点之间通常通过复制的方式来实现数据的同步,比如Mysql的的基于binlog的主从同步,Redis的基于sync/psync机制的aof主从同步,MongoDB基于oplog的主从同步等等。这些机制支撑了一个单元下的数据冗余高可用和读写分离负载分担。
但仅仅一个逻辑单元内的数据同步对于很多业务通常不够用,很多业务需要跨逻辑单元的数据同步的能力,例如同城多机房,异地多数据中心同步等。容灾,多活是最常见的两种业务场景,扩展开来还可以有读写分离,负载分担等多种场景。现在越来越多的公司选择将基础业务部署到云上,那么这些能力都需要云厂商能够提供,以提高服务的质量,更好的为用户的业务服务;另外,最近混合云场景大热,其原因有多种,既有云厂商的原因,也有用户业务变化的原因,但这最终要求了从云下到云上,云上到云下,跨云不同云厂商之间的互相同步的能力。
1.1 容灾
容灾通常用于数据的备份,备份数据对外不提供服务,或者仅提供读服务,在机房发生故障的时候,备份数据库代替原数据库对外提供服务。一般来说,业务的服务治理模块发现原服务不可用后,选择代理层进行流量的转发,或者采用DNS进行切流,其机制基本类似,都是将发送到原数据库的流量转发到备份数据库。容灾系统对RPO(故障恢复时间)和RTO(恢复数据的时间点)都有要求,比如故障要求3分钟内恢复,恢复的数据最多容忍丢失1s,这些都需要数据同步和服务治理发现配合完成。如果RPO和RTO的要求很高,那么全量备份通常不可取,因为全量备份通常是定期的,比如一天一次,假如故障的时间恰好发生在全量备份之前,这意味着这接近一天的数据丢失了,数据只能恢复到一天之前。所以这就要求了具有一个实时增量的热备份能力。
因为数据的全量和增量不断同步,例如Redis的RDB文件和AOF文件,如果Redis发生不可服务,这些RDB+AOF文件可以恢复成一个数据库继续提供服务。再譬如MongoDB的全量snapshot+oplog增量,也可以恢复成一个完整的数据库。
另外,备份还可以分为逻辑备份和物理备份,逻辑备份通常指的是数据库的逻辑层面通过全量文件+binlog文件来实现,而物理备份通常指引擎层面来进行备份。
以上提到了关于备份,有很多划分种类,比如冷、热备份,冷、热恢复,物理、逻辑备份,全量、增量备份等等,关于这些概念如果不清晰可以自行搜索一下。此外,我们在本小节的开头提到,备份还可以提供一个读服务,那对于这种场景来说,备份数据不能单单是一些文件,例如RDB文件,AOF文件等,而需要是一个完整可服务的数据库,所以这种场景下,通常也需要是一个实时增量的热备份。
1.2 多活
多活对于数据库层面来说,指的是跨逻辑单元的多个数据库同时对外提供服务,这些不同单元的数据库具有部分相同或者全部相同的数据。这通常用于解决因地域网络传输层面带来的问题,也就是异地多活,比如业务层面在北京机房写入一条数据,要求在上海机房也能读到这条数据;同样反过来也可以,在上海机房写入的数据,在北京也能读到。
多活的模式看起来很好,能解决很多业务层面的问题,但同时有很多问题和挑战:
- 如何解决双向复制的问题?两个数据库互相同步数据,那难免数据会成环导致风暴。举个例子,假如A数据库和B数据库互相同步,我在A数据库插入一条数据:insert x。那么这条数据通过同步链路会被同步到B数据库,这时候B数据库也插入了这条数据:insert x。又由于反向同步链路的存在,这条数据又会被同步回A数据库: insert x。长此往复,数据就成环了。该怎么办呢?答案就是,这种双向复制如果仅依赖通道层面来解决基本不可行,通常需要配合数据库内核或者业务层面来解决。比如数据库内核增加全局唯一字段,标识数据产生地,而通道在拉取数据时,只拉取
数据的产生地id=当前数据库id的数据,打破成环;亦或者,在链路层面增加过滤,比如从源库只拉取db=a,b的数据,从目的库只拉取db=c的数据,这样数据保证不会成环,而源和目的两个库都有全套的db=a,b,c三个数据库的数据,然后通过业务层面配合,将db=a,b库的写数据分发到源库,db=c库的写数据分发到目的库来实现。对于开源数据库模式下,第二种模式也是最常见的模式,在后面介绍MongoShake和RedisShake我们会详细介绍这种模式。 - 如何解决数据双写的问题?也就是说,如何保证在两个数据库同时对一条数据进行操作,而结果是正确的。同样举个例子,假设在源数据库A和目的数据库B有一条数据x=1,我先在A库操作了
set x=2,而后在B库操作了set x=3,那么能保证最后2个库的结果都是3吗?答案是否定的,因为数据同步是最终一致性,而最终一致性势必是有时间窗口的。在B库操作set x=3的时候,可能A库之前的set x=2语句还没有完成同步,那么先set x=3,后同步set x=2,结果目的端就变成了2,而源端同步了set x=3结果变成了3,这样数据就变成了不一致。当然我这里只是随便举个例子,还有很多不一致的情况。那么解决这种问题同样也需要两种手段,其一就是内核层面,其二就是业务配合解。内核层面解决的比如CRDT,其基于一个向量时钟来处理消息的分发,那么向量时钟也会带来冲突,对于冲突的处理需要借助一些手段,比如last write win,客户端解决等等。而很多数据库本身对CRDT的支持很不够,所以这种方案有比较大的局限性。其二就是类似我在如何解决双向复制的问题里面讲到的,对业务流量进行分流解决,由业务保证不会在同步通道的两侧同时对一条数据进行操作。
现在数据库层面的多活,大部分都是一种伪多活,通常都需要业务层面配合分流来解决。下面我在MongoShake和RedisShake章节,会对这种业务配合的方式进行展开讨论。
2. 迁移
从广义来说,迁移应该算是同步的一种模式。同步侧重于增量,而迁移侧重于全量。迁移通常说的是数据库的搬迁,将源数据库搬迁到目的数据库,搬迁之后目的数据库代替源数据库继续提供服务,源数据库可以选择下线或者继续提供服务。
迁移有多种场景,比如同种数据库下异构模式迁移,例如Redis的主从版迁移到集群版;可以是数据库的升级迁移,比如MongoDB从3.0升级到4.0;也可以是上云迁移,比如云下的数据库迁移到云上,或者云上的迁移到云下等等。迁移的同时,源数据库可写可不写,不写的话稍微简单一些,迁移往往不需要迁移增量,只需要做全量迁移即可,但这通常需要业务停写,很多业务难以接受;可写的话比较符合大部分业务场景,但对迁移的链路就需要有个全量+增量迁移的能力。等迁移完毕,用户可以对迁移后的数据进行校验,发现没问题了,等待一个业务时间点进行一次闪断切流,将流量分发到目的端,数据就完成了迁移,源数据库就可以下线了。
上述我提到了,迁移可以用于云下到云上,云上到云下这种混合云场景的迁移。但现在对于很多云厂商来说,从云上到云下的迁移可能比云下到云上的迁移困难一些,因为云上到云下的同步需要能够从云上拉取数据,对于一些数据库来说,这些拉取的权限很可能没有开放。例如Redis的sync迁移,需要源端开放sync/psync权限,而很多云厂商出于安全角度考虑是不支持的。这就对迁移工具提出了另一个挑战,而应对这个挑战的方式要么就是云厂商支持这种模式,要么就是换一种其他迁移方式。对于阿里云来说,已经开放了用户的复制权限,使得用户可以通过sync/psync进行数据的拉取。另外,RedisShake本身也支持了其他绕过sync/psync的同步迁移方式,后续我都会介绍。
3. MongoShake & RedisShake同步迁移工具
阿里云开源了MongoShake和RedisShake,可以用于MongoDB和Redis的同步和迁移,进一步实现用户对灾备和多活的需求。
3.1 MongoShake
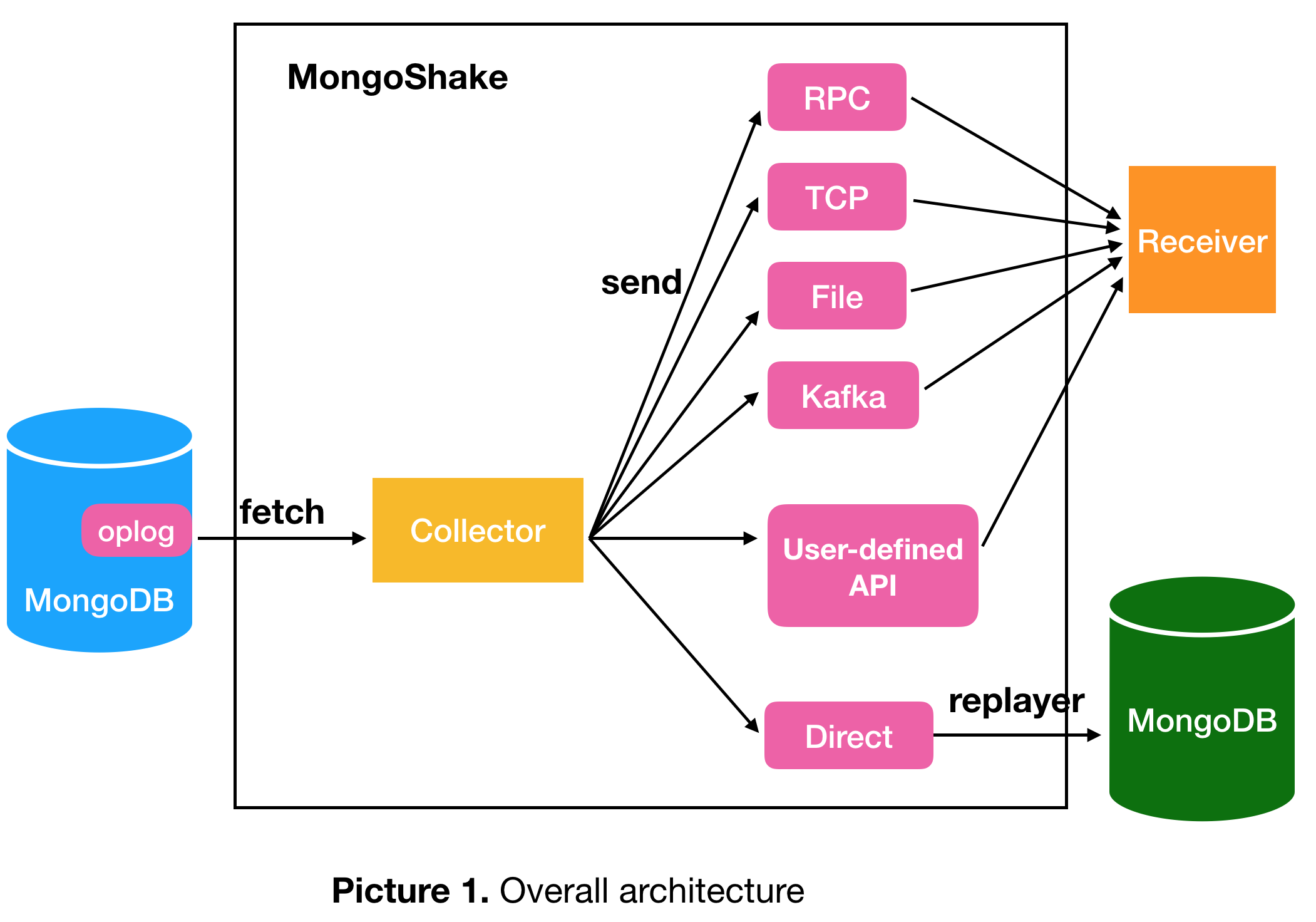
MongoShake的同步是基于oplog实现的,v1.5版本开始支持全量同步,其内部具体实现细节可以参考我在云栖社区上写的文章。本小节主要从功能和应用场景来进行介绍。
首先介绍一下主要的功能:
- 全量同步。从源端拉取全量数据写入到目的端。
- 增量同步。拉取源端的增量数据,写入到目的端。作为同步迁移工具,MongoShake最主要的功能肯定是数据的同步,全量加增量就是实现数据同步的基础。上面我们提到的灾备和多活功能就是基于这两个来实现的。
- 过滤。MongoShake支持对数据按库、表过滤,这样就能够实现我们在前面提到的,双向同步的场景。
- 并行复制。MongoShake内部采用了并行复制的策略,使得最高的QPS可以达到40W。
- 压缩。MongoShake支持对数据进行压缩,通常用于远距离传输的场景。
- HA。MongoShake可以支持集群HA切换,用户可以通过启动多个MongoShake来启动主备集群。
- 断点续传。MongoShake通过持久化checkpoint信息来支持同步链路断开重连后,数据能够重新接上进行传输。
- 灵活多通道支持。MongoShake除了支持将源数据写入目的库以外,还支持多种通道,比如tcp/rpc/file/kafka等,满足用户不同的需求。例如,MongoShake可以将数据写入kafka,用户可以从kafka中拉取数据,然后对接到流式计算平台满足实时计算的需求。用户甚至可以自定义通道类型,满足特殊的业务需求。
下面来简单列举一下,有了这些功能,我们可以做什么?也就是说应用场景有哪些?
- MongoDB集群的异步复制,减少业务双写的开销。
- MongoDB集群的灾备、多活、读写分离等业务部署。
- 基于MongoDB oplog的日志分析平台。
- 基于MongoDB oplog的日志订阅。用户可以从例如kafka通道中拉取日志,然后对感兴趣的日志进行订阅。
- MongoDB集群的数据路由。根据业务需求,结合日志订阅和过滤机制,可以获取关注的数据,达到数据路由的功能。
- 基于日志的集群监控。
- Cache的反向同步。可以通过日志分析的结果,知道哪些Cache可以被淘汰,哪些Cache可以进行预加载,从而反向推动Cache的更新。
以上只是简单列举了几种应用场景,如果你有不同的玩法或者不同的业务需求,也欢迎跟我联系,MongoShake产品还在持续迭代更新中,后续还会有很多有用且好玩的特性会进行持续添加。
3.2 RedisShake
RedisShake的同步是基于向源Redis发送sync/psync命令,然后实现全量+增量拉取并回放来实现的。同样,具体细节介绍请参考我在云栖社区发表的博客,本文主要从功能角度进行介绍。
RedisShake目前主要有以下5大功能:
- dump。从源Redis将全量RDB文件下载下来。
- decode。解析指定的RDB文件。
- restore。目的库根据指定的RDB进行全量恢复。
- sync。支持数据同步,源端可以是单节点Redis,主从Redis,集群Redis,也支持codis,目的端同样也可以是各种模式的Redis。
- rump。支持对源端进行key扫描并全量迁移。这个主要是应对一些云厂商没有开放sync/psync权限的情况下,进行全量迁移的场景。

RedisShake的sync模式是目前使用最为广泛的模式,其通过RDB全量并发同步,以及增量异步写入的方式来提高同步的性能,理论上可以达到毫秒级别的同步延迟。此外,用户还可以根据redis-full-check来进行数据同步后的一致性校验,保证数据的正确性。
RedisShake的场景以同步为主,如果用户有特定的需求,也欢迎告知我们,比如类似MongoShake的离线计算等场景。目前RedisShake处于刚开源阶段,功能点迭代比较快,欢迎大家关注。
4. 使用案例
本节主要介绍一下用户根据我们的MongoShake和RedisShake的使用案例
4.1 高德地图
高德地图 App是国内首屈一指的地图及导航应用,阿里云MongoDB数据库服务为该应用提供了部分功能的存储支撑,存储亿级别数据。现在高德地图使用国内双中心的策略,通过地理位置等信息路由最近中心提升服务质量,业务方(高德地图)通过用户路由到三个城市数据中心,如下图所示,机房数据之间无依赖计算。
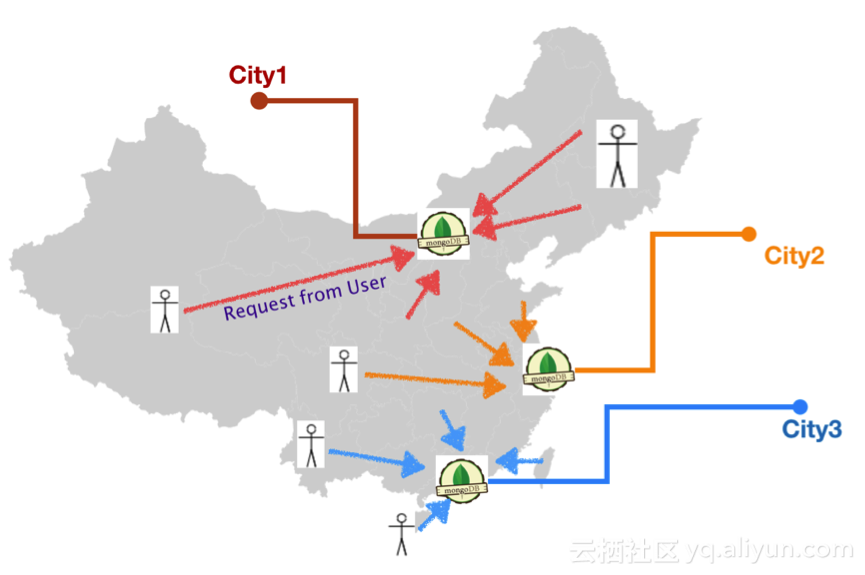
这三个城市地理上从北到南横跨了整个中国 ,这对多数据中心如何做好复制、容灾提出了挑战,如果某个地域的机房、网络出现问题,可以平滑的将流量切换到另一个地方,做到用户几乎无感知?
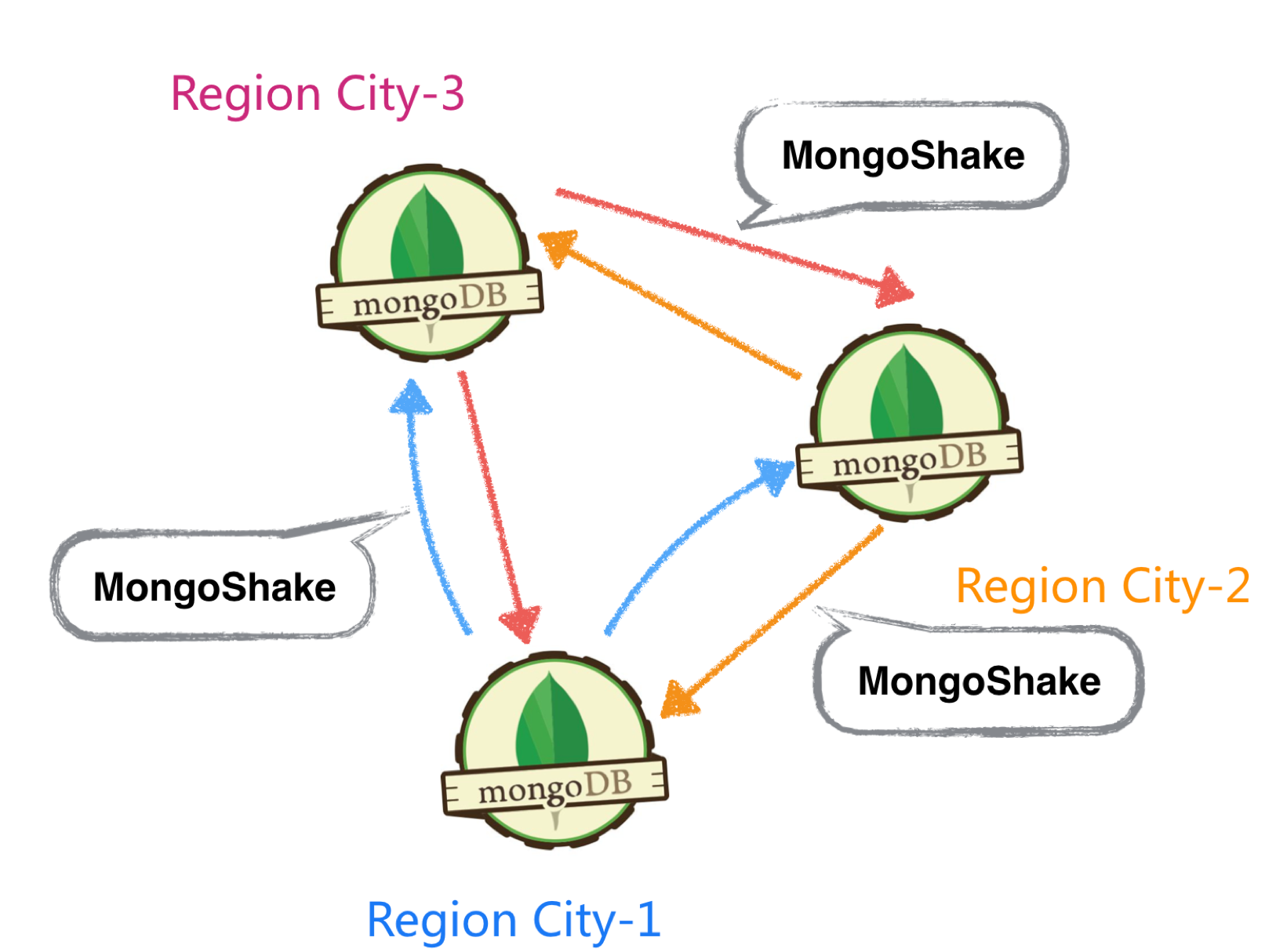
目前我们的策略是,拓扑采用机房两两互联方式,每个机房的数据都将同步到另外两个机房。然后通过高德的路由层,将用户请求路由到不同的数据中心,读写均发送在同一个数据中心,保证一定的事务性。然后再通过MongoShake,双向异步复制两个数据中心的数据,这样保证每个数据中心都有全量的数据(保证最终一致性) 。如下图所示:
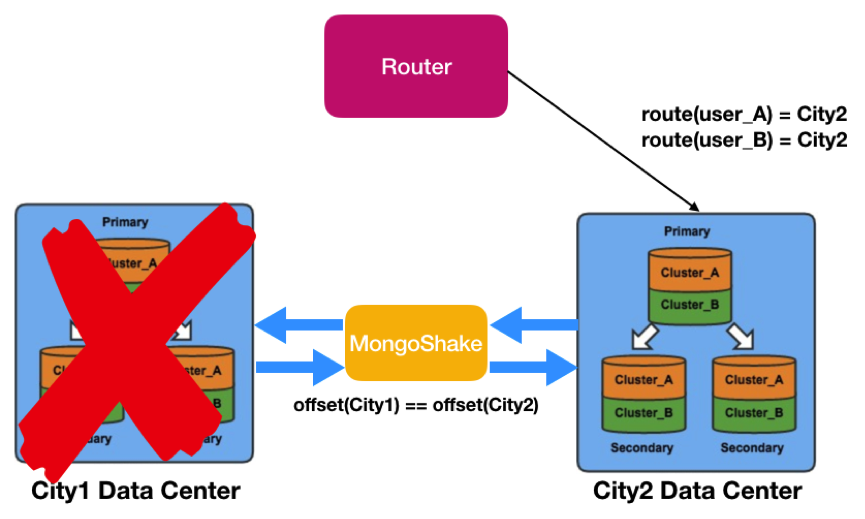
任意机房出现问题,另两个机房中的一个可以通过切换后提供读写服务。下图展示了城市1和城市2机房的同步情况。
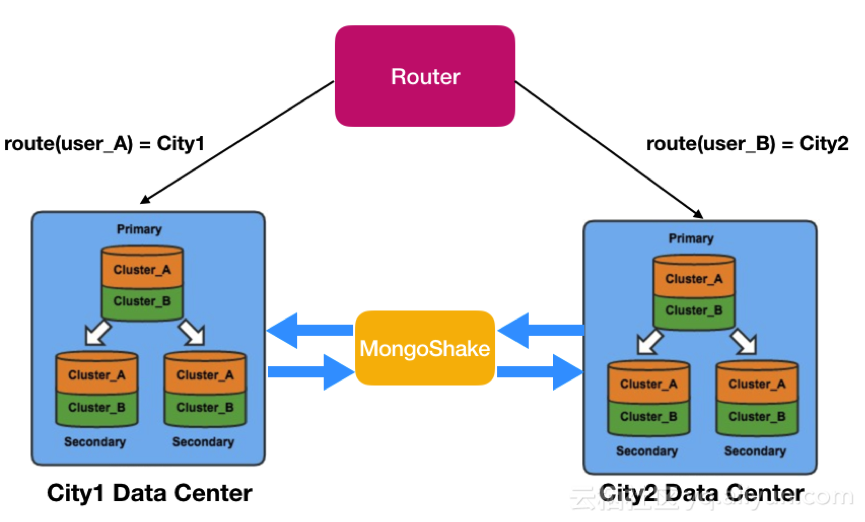
遇到某个单元不能访问的问题,通过MongoShake对外开放的Restful管理接口,可以获得各个机房的同步偏移量和时间戳,通过判断采集和写入值即可判断异步复制是否在某个时间点已经完成。再配合业务方的DNS切流,切走单元流量并保证原有单元的请求在新单元是可以读写的,如下图所示。
4.2 某跨境电商
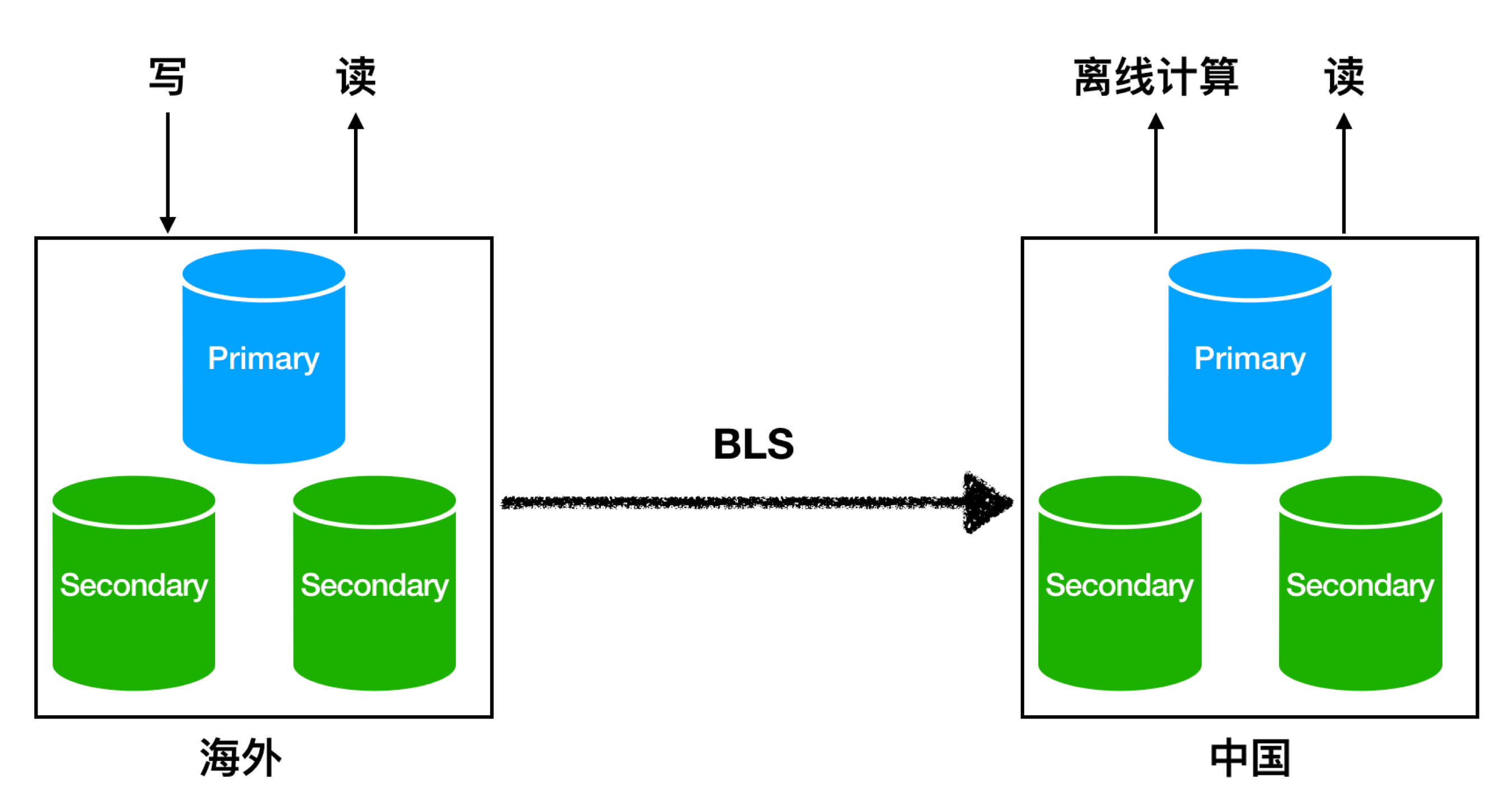
某跨境电商在中国和海外分别部署了2套MongoDB,其中海外主库上提供读写服务,同时用户希望把海外的数据拉到国内进行离线计算,以及承担一部分读流量,以下是该用户采用MongoShake搭建的链路方案:
4.3 某著名游戏厂商
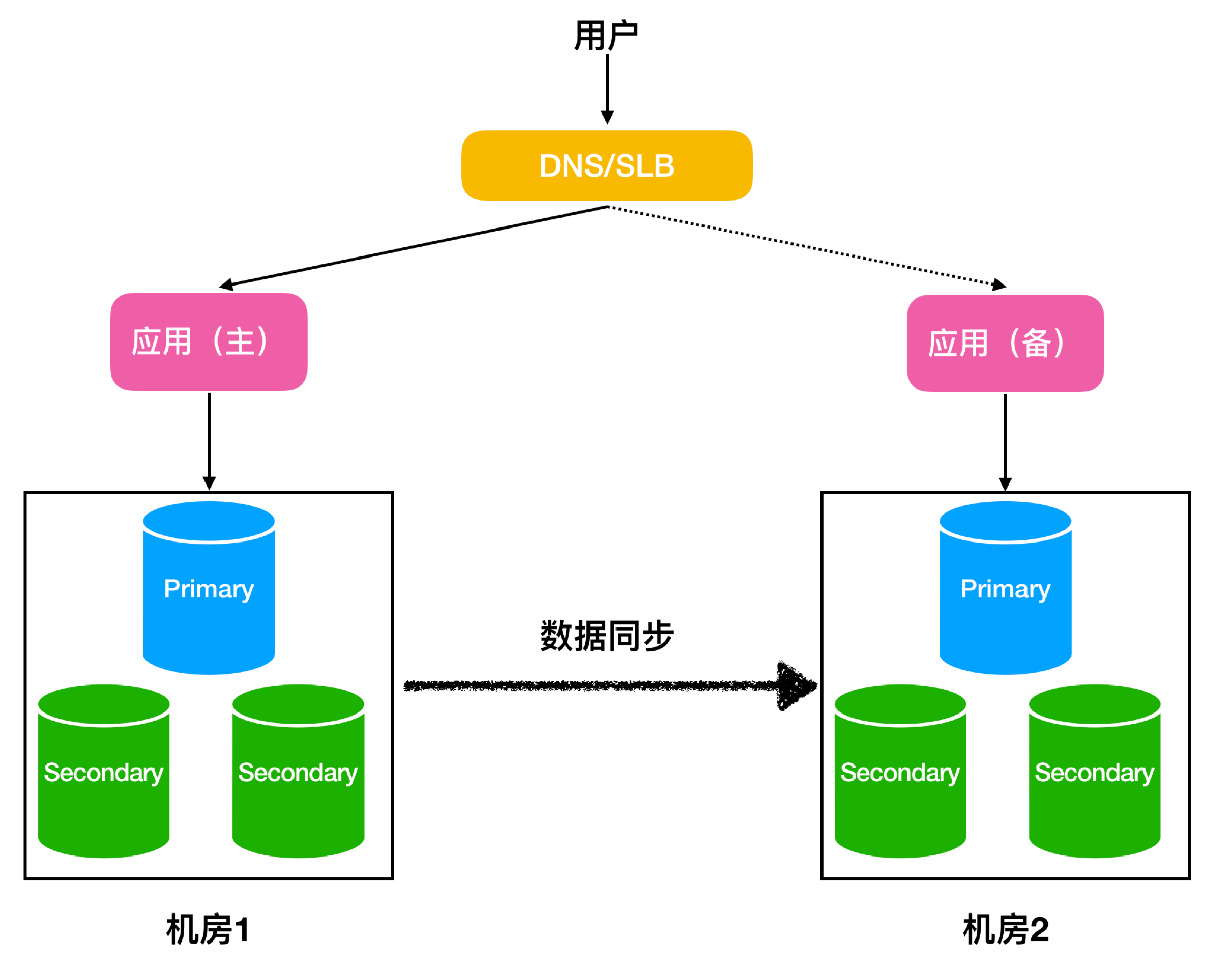
某著名游戏厂商采用了MongoShake搭建了异地容灾链路。用户在2个机房分别部署了2套应用,正常情况下,用户流量通过北向的DNS/SLB只访问主应用,然后再访问到主MongoDB,数据通过MongoShake在2个机房的数据库之间进行同步,一旦机房1不可用,DNS/SLB将用户流量切换到备上,然后继续对外提供读写服务。
4.4 采用Shake的开源多活方案
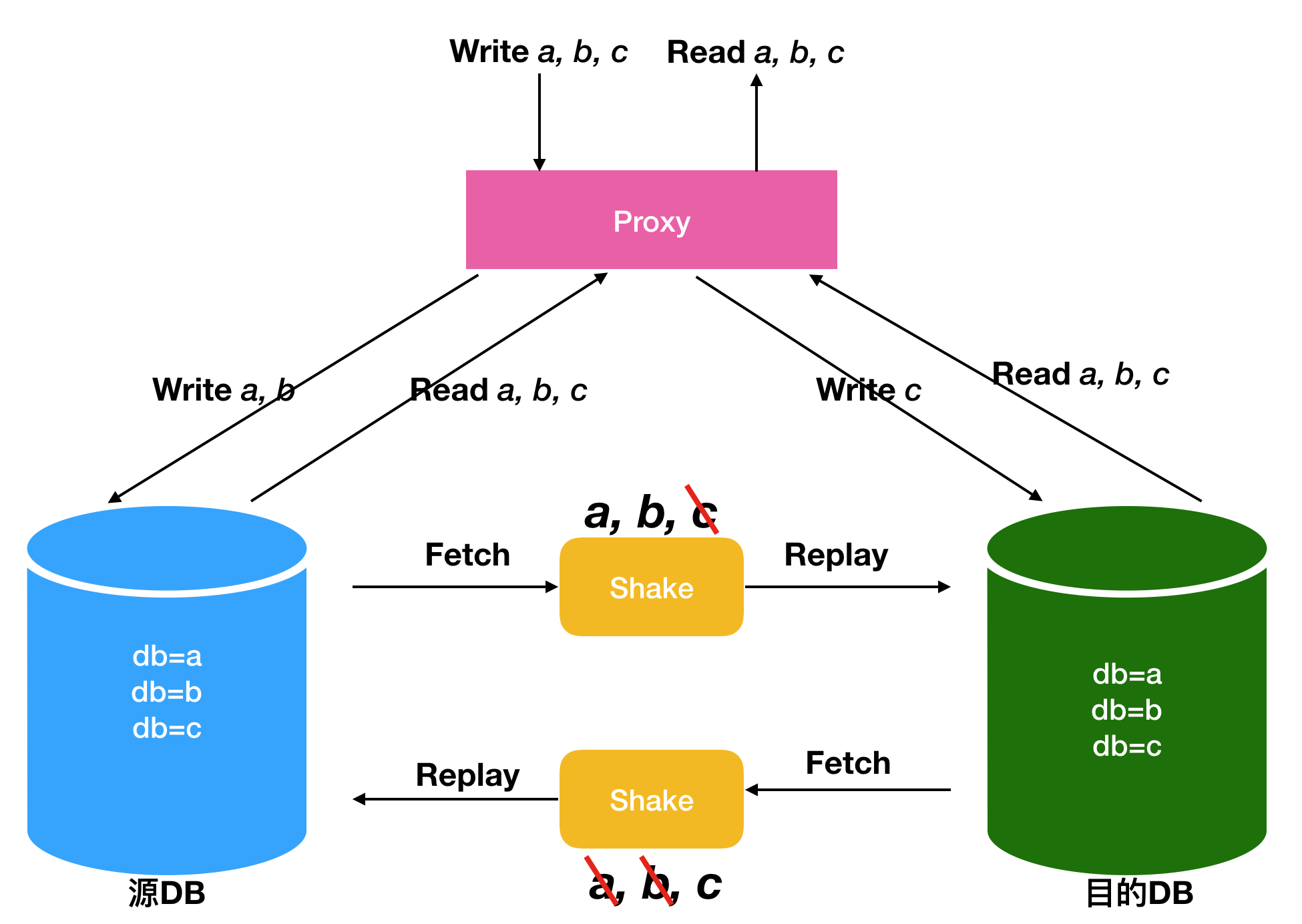
这里是我们给出的根据Shake创建多活的方案,包括MongoShake和RedisShake。上文我们介绍在开源MongoDB下,可以根据控制流量分发来达到多活的需求。比如下面这个图,用户需要编写一个proxy进行流量分发(红色框),部分流量,比如对a, b库的写操作分发到左边的DB,对c库的写操作分发到右边的DB,源库到目的库的Shake链路只同步a, b库(MongoShake和RedisShake均提供按库过滤功能),目的库到源库的Shake链路只同步c库。这样就解决了环形复制的问题。
总结来说,也就是写流量通过proxy进行固定策略的分发,而读流量可以随意分发到任意DB。
4.5 采用Shake的级联同步方案
这个是一个全球的部署的用户采用Shake搭建的全球混合云级联方案的示例图,有些数据库位于云上,有些位于云下,Shake提供了混合云不同云环境的同步,还可以直接级联方式的集群同步。
5. 总结
总结主要介绍了一下数据库同步和迁移的场景,然后结合功能和应用场景介绍了下我们开源的两款Shake工具。目前,我们的Shake工具还在持续功能迭代中,欢迎关注我们的github:
有任何问题欢迎在github上进行提问,也欢迎分享你们的使用场景,以帮助我们更好的完善产品。
参考
https://github.com/alibaba/MongoShake
https://github.com/alibaba/RedisShake
https://github.com/alibaba/RedisFullCheck
https://hal.inria.fr/inria-00609399/document?spm=a2c4e.11153940.blogcont635632.9.1fea5b58HAOwS2
https://yq.aliyun.com/articles/691794
https://yq.aliyun.com/articles/603329