
PortLand是2009年提出的一种数据中心架构模式,它解决了传统架构的几种不足,具有以下几个优点:虚机迁移IP不变且原连接正常;部署前不需要人工配置交换机;任意主机可达;无环;链路失败检测。PortLand采用的是二层架构模式,方便扩容、迁移,同时解决了二层ARP,广播等带来的问题。
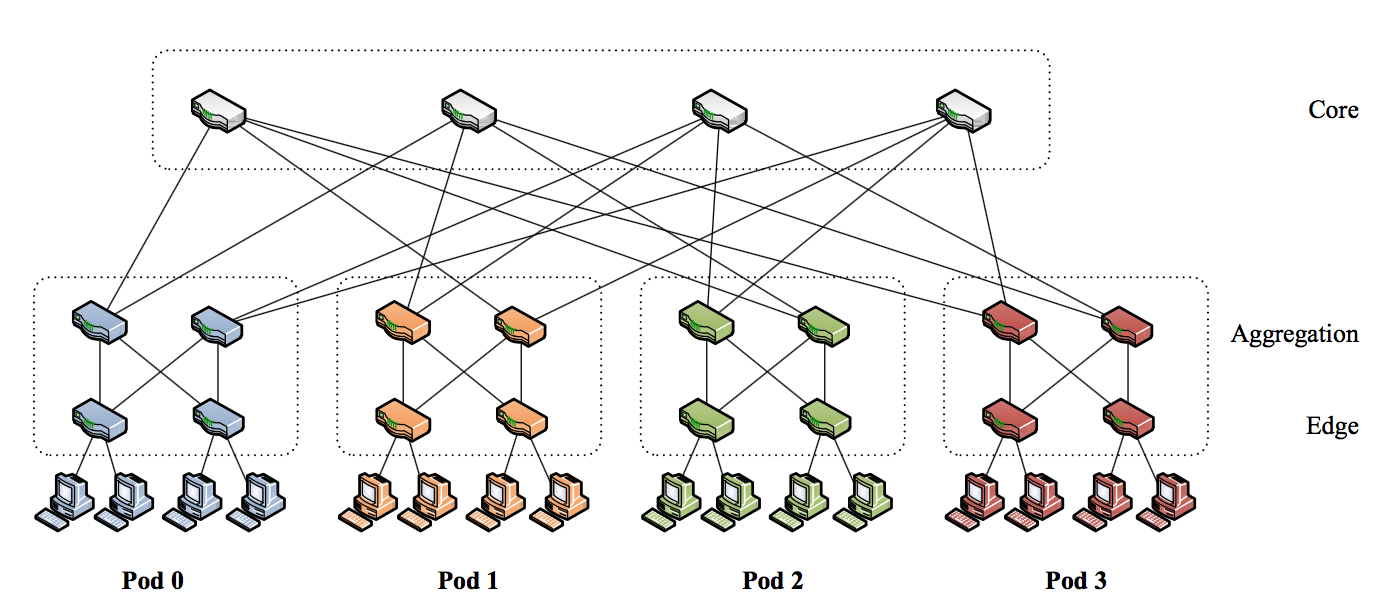
下图是几个胖树拓扑(Fat tree)的例子,也是PortLand采用的拓扑。拓扑为三层拓扑,从上而下分别是核心层、汇聚层和边缘层。边缘交换机下连主机,上连汇聚层,一个主机连接一个边缘交换机。几个汇聚层交换机(文中为2个)和几个边缘交换机(文中为2个)互连组成一个Pod。每个汇聚层上连2条链路到核心层,注意一个Pod上连的核心交换机各不相同,这是为了充分负载和容错的考虑。
1.Fabric Manager
Fabric Manager(以下简称FM)为集中化管理的软件,主要用于处理ARP,链路容错以及多播报文等问题。为了保证健壮性,同样对FM做主备,防止单个FM失败带来的全网不通的问题。
2.MAC地址
二层架构导致了MAC地址成为本文问题的关键。PortLand提出了PMAC的概念(Pseudo MAC),也就是一个层次化的假的MAC地址,每台主机分配一个PMAC地址,同时主机还有一个AMAC(Actual MAC),即原MAC地址。主机在访问别的主机时会修改目的和源主机的AMAC地址为PMAC地址,这部分工作由源主机上联的边缘交换机完成,然后,在目的主机上联交换机处将目的PMAC改为AMAC,使得报文可以送达目的主机。
PMAC地址的格式如下:pod.position.port.umid。其中,pod(16 bits)代表边缘交换机所在的pod号码;position(8 bits)表示pod内部的位置;port(8 bits)表示主机所上连的边缘交换机的端口号;umid(8 bits)为主机标识号,递增序列,且存在超时机制,超时则回收并重新使用。
下图给出了一个AMAC到PMAC映射的例子。当一个边缘交换机发现某个MAC地址(AMAC)未被学习过,则报文被至FM,FM创建AMAC+IP到PMAC的映射,该条目下次用于回复ARP。
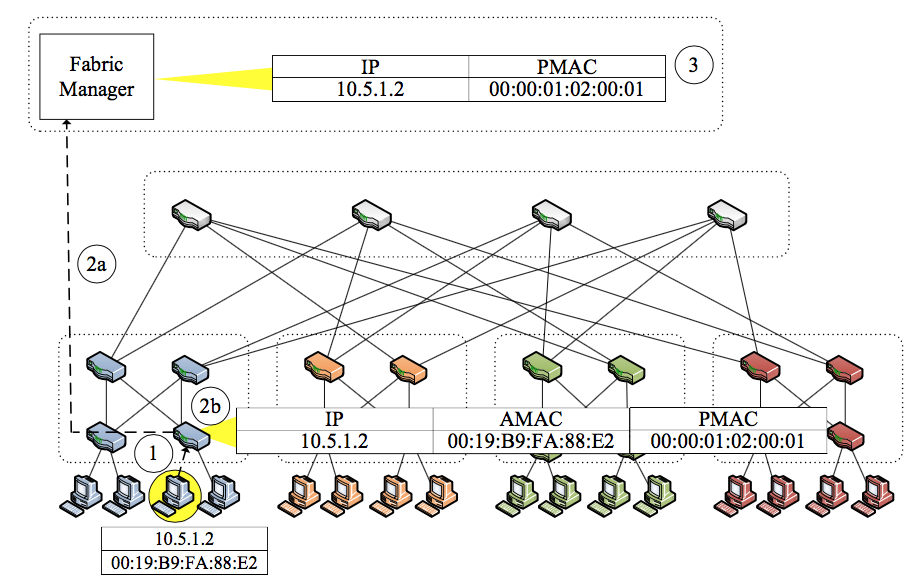
设置PMAC的本质是为了分离位置信息和名字信息,使得主机同时具有位置(PMAC)和名字(AMAC)两大信息,方便了主机的迁移,即只需要变更PMAC。我们可以用OpenFlow协议很好的实现本节的内容。
3.ARP
下图展示了FM处理ARP报文的过程,首先是边缘交换机收到ARP报文请求,然后送至FM,FM查表目的PMAC,若有则返回消息,最后边缘交换机发回ARP reply。当然,也可能存在FM不存在目的PMAC的情况,这时候,FM将会发送广播请求给所有主机,然后获取映射关系:ARP先发给核心交换机,然后转发至各个Pod,最后到边缘交换机,再到主机,主机再返回reply给边缘,此时对于之前不存在的主机,将建立映射关系,最后FM将会得到这个映射告知源主机。
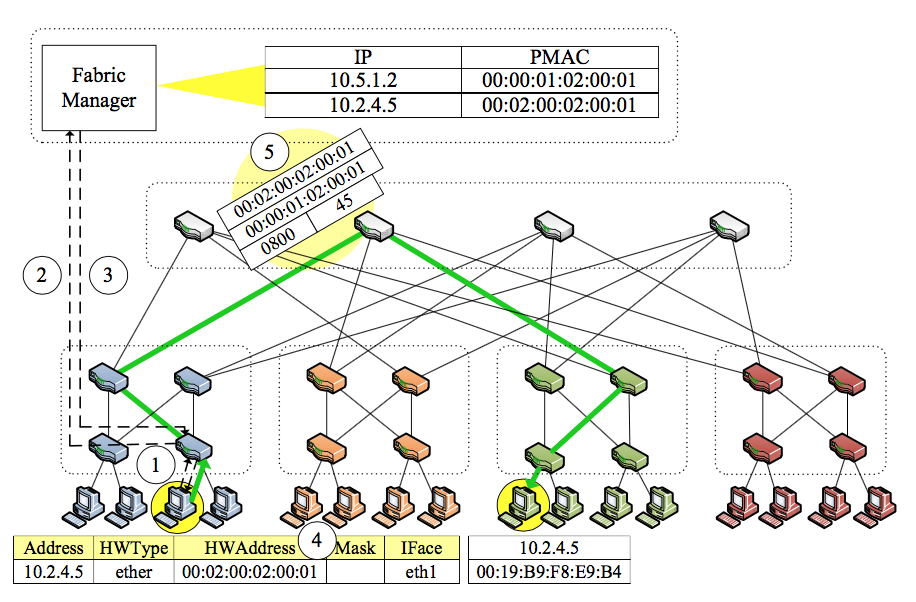
需要特殊处理的情况是虚机迁移,一旦一个虚机从一个物理机迁移到另外一个物理机,该虚机将会发送新的IP到MAC的映射给边缘层再给FM。FM发送一条无效消息给虚机之前上联的边缘交换机,告知原映射缓存失效。被动触发更新:若有新连接仍然来到原边缘交换机,则交换机回复新的虚机位置(即新的映射关系),并可以重新转发流量给新的虚机(可选)以保证报文不丢失。
4.位置探测协议
PortLand推出了LDP(Location Discovery Protocol)协议确定各个交换机的位置(核心、汇聚、边缘),PortLand交换机定期从每个端口发送LDM(Location Discovery Message),用于保活和更新交换机位置。LDM报文包括以下信息:
- Switch identifier(switch_id):交换机的唯一id。
- Pod number(pod):Pod号码。
- Postition(pos):每个pod内的边缘交换机都有唯一的pos号码。
- Tree level(level):0,1,2,分别标识核心、汇聚、边缘。
- Up/down(dir):标识交换机的端口是上联还是下联。
LDM报文的传播可以确定层级关系。边缘交换机只会从和汇聚交换机相连的端口才会收到LDM报文,边缘交换机可以通过连接主机来确定自身关系(只有边缘交换机才会与主机相连接),汇聚交换机可以通过连接边缘交换机来确定自身关系(只有汇聚交换机才会连接边缘交换机),核心交换机可以通过其所有端口都连接汇聚交换机来确定自身关系(核心交换机只与汇聚交换机相连接)。具体执行算法如下:

所有交换机都将定期发送ping(我的理解应该类似是Hello报文),所有连接的交换机和主机都将回复ping但只有交换机才会传送LDM而主机不会。
刚开始的时候,每个边缘交换机都将根据以下算法申请一个pod内的唯一pos号码:

5.无环链路
注意,在三层架构中,从边缘到汇聚,和从汇聚到核心都可以采用ECMP路径。层级递送报文保证了一旦报文往下传送(从高层到底层),报文不会回传(从底层到高层),也就是不会导致环路。
6.容错路由
6.1单播报文路由容错
下图展示了一个单播报文路由容错的例子。
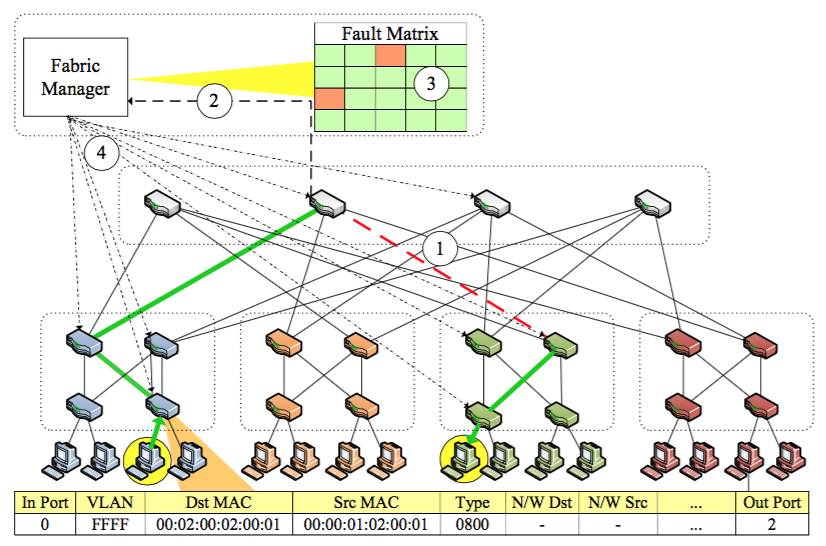
- 核心交换机未定时收到LDM报文
- 核心交换机告知FM链路故障
- FM更新拓扑信息
- FM告知所有交换机链路更新,初始交换机更新转发表。
在传统链路协议中,n个交换机需要交换O(n^2)个报文才能更新所有链路,而PortLand中所有交换机都和FM交换链路消息,所以只需要O(n)个报文即可。
6.2多播/广播报文路由容错
下图展示了一个多播报文路由容错的例子。
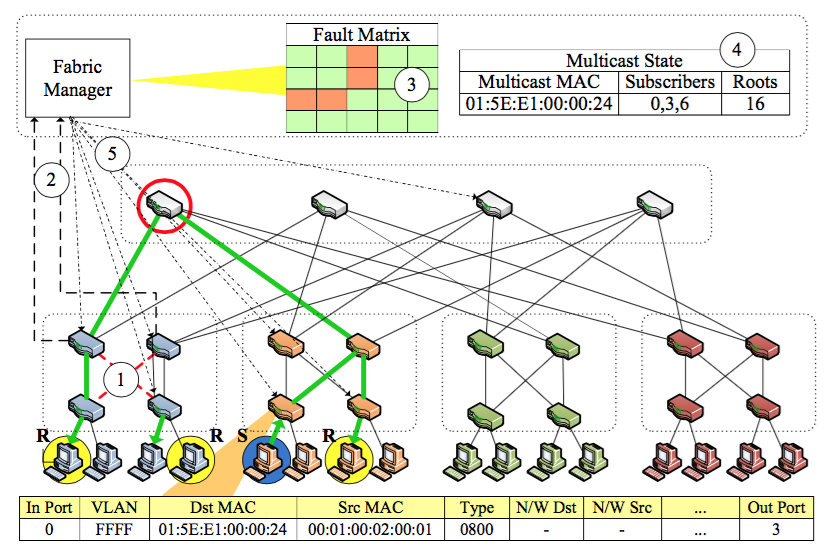
注意,主机S发送多播报文到3个R,位于pod0内的两条链路锻炼,导致R2无法收到报文。注意这里是多根树,此时的策略是重新计算一个包括所有多播目的主机的贪心集合(核心交换机),让报文发往所有集合内的根(核心交换机),然后完成转发,如下图所示。
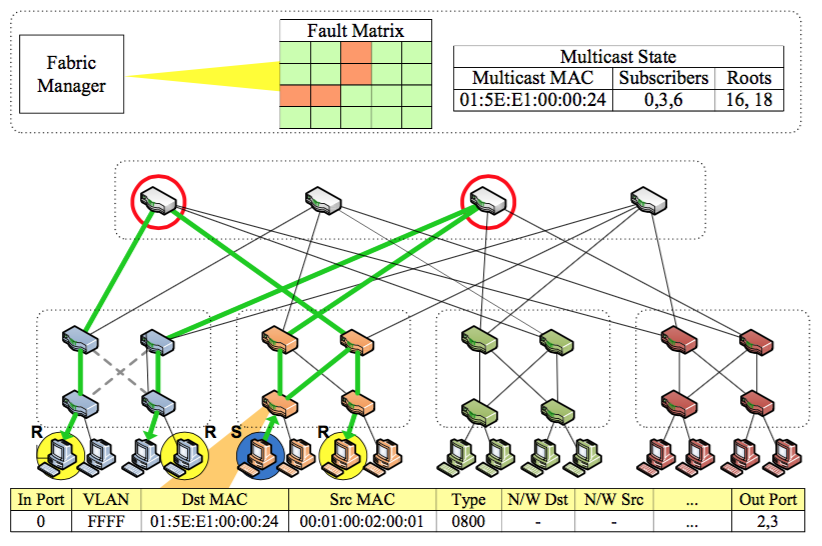
说明
本文阅读匆忙,可能存在部分不足,若有不对之处,望指正。
转载请注明出处:http://vinllen.com/portlandshu-ju-zhong-xin-jia-gou/
参考
Niranjan Mysore R, Pamboris A, Farrington N, et al. Portland: a scalable fault-tolerant layer 2 data center network fabric[C]//ACM SIGCOMM Computer Communication Review. ACM, 2009, 39(4): 39-50.