
本文首先介绍MongoDB 4.2版本,MongoDB主从复制中增量同步的拉取和写入流程,然后介绍几个位点的区别:lastApplied,lastCommit,stableCkpt,appliedThrough。
1. 增量同步基本流程
secondary的OplogFetcher负责从源端拉取oplog,并写入到内存blocking队列OplogBuffer中;OplogApplier负责从oplog中拉取数据,并写入到目的端(也就是当前结点)。下图是增量同步的基本流图:
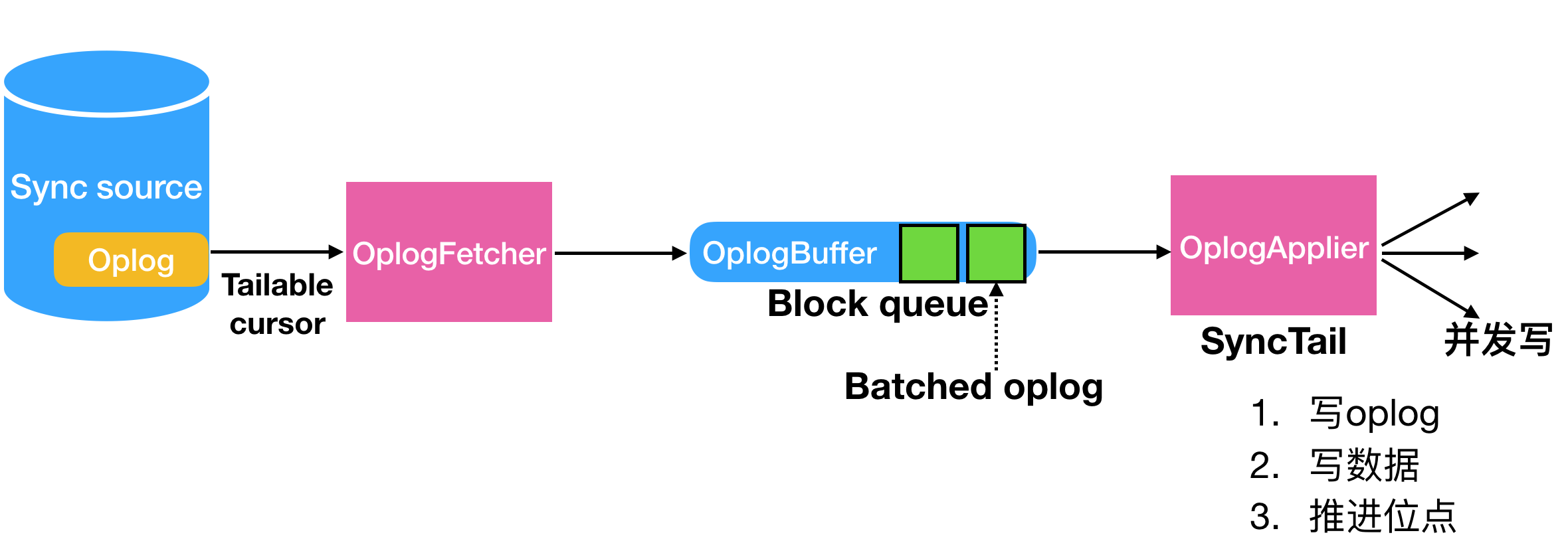
同步之前,secondary会选择一个sync source作为同步的源进行全量和增量的拉取,那么同步源是如何选择的?
1.1 同步源sync source的选择
每次开启全量intial sync,创建BackgroundSync的时候,必须先获取一个sync source,这个过程就是通过SyncSourceResolver来完成的。SyncsourceResolver代理ReplicationCoordinator去进行选择sync source,其内部是通过调用TopologyCoordinator进行完成。
TopologyCoordinator如何进行选择:
- 判断是否用户强行指定primary(replSetSyncFrom命令),是的话直接选择用户指定的sync source
- 判断链式复制选项是否被disable,是的话直接选择当前primary作为sync source
- 重复以下几个步骤直到完成选择
- 检查TopologyCoordinator中cache的副本集的OpTime的信息。(当前结点缓存的primary节点上关于各个节点最新的同步时间)
- 通过检查TopologyCoordinator上缓存的拓扑里面的primary的OpTime。secondary并不会选择那些secondary节点落后primary超过maxSyncSourceLagSecs时间间隔的节点。
- secondary迭代各个节点,选择满足various criteria的ping延迟最低的结点作为sync souce.
- 如果没有节点满足要求,则sleep 1s并重试4-7三步骤。
选择完sync source以后,SyncSourceResolver会对sync source进行探测以观察是否有异常。
- 如果sync source没有oplog或者有异常,那么这个sync source会被拉入到黑名单持续一定的时间,并重新发起sync source的选举。
- 如果sync source的最老的oplog大于当前结点最新的oplog,那么这个sync source同样会被拉入黑名单,并重新选举。
- 在initial sync,rollback或者recovery期间,结点都将会设置OpTime(local.repliaset.minValid表),其中begin字段存在则表示不一致状态,如果存在不一致状态,那么secondary需要检查这个ts在primary上是否存在。关于minValid的知识,主要是用于检测需要的oplog还是否存在,具体请参考MongoDB Primary为何持续出现oplog全表扫描。
- 拉取sync source的RollbackID用于检测source是否发生回滚
如果结点落后所有结点太多,则无法选择sync source,需要人为介入,比如执行resync命令(由于各种问题,在3.6版本之后resync被废弃了)。BackgroundSync会一直重复选举,直到找到一个sync source,并启动OplogFetcher进行增量的拉取。
2. OplogFetcher
secondary通过OplogFetcher从主上进行拉取oplog,其原理就是采用find+getMore命令来进行。最初的find请求必须有返回(>=1个文档),如果没有则表示现在的源不适合作为sync source(源落后于secondary);如果有,但是拉取的第一条oplog不等于secondry上的最后一条,那么说明当前结点的数据需要进行回滚(回滚到上一个stable checkpoint)。secondary需要对拉取的结果进行检查,以判断目前的源是否ok,以及是否需要回滚。
OplogFetcher采用{awaitData: true, tailable: true}配置项进行长期拉取,如果出错将会重启Fetcher(最多3次)。OplogFetcher是跑在BackgroundSync线程内部,只要是secondary节点位于SECONDARY状态(其实还包括STARTUP2)该线程会一直循环跑。除非碰到:
- 拉取的oplog位点在源端丢了 (重新全量);
- 拉取的oplog不等于secondary上的最后一条(需要回滚)
- 网络等原因出错(重试)
- secondary结点退出(bgsync线程也会退出)
OplogFetcher拉取完数据后,并不是直接应用,而是将数据塞入到OplogBuffer中,OplogBuffer是一个内存的block queue(大小256MB),这个队列写满了相当于拉取就暂停了。有独立的线程从这个队列里拉取并进行apply。
3. OplogApplier
OplogApplier调用SyncTail负责从OplogBuffer中进行oplog的batch拉取以及回放。拉取是串行拉取,拉取到一批batch的oplog以后,调用多线程进行并发写入,首先批次并发写入oplog(不需要保证顺序),然后批次写入数据(保证_id有序即可,wiredTiger为doc级别锁,所以doc层次并发),最后推进各个位点。
以下是结合代码拉取oplog并写入的具体过程:
3.1 启动OplogApplier::startup
刚开始OplogApplier启动线程,内部调用OplogApplierImpl::_run。
3.2 OplogApplierImpl::_run
void OplogApplierImpl::_run(OplogBuffer* oplogBuffer) {
auto getNextApplierBatchFn = [this](OperationContext* opCtx, const BatchLimits& batchLimits) {
return getNextApplierBatch(opCtx, batchLimits); // 从oplogBuffer里面获取下一个batch的方法
};
_syncTail.oplogApplication(oplogBuffer, getNextApplierBatchFn, _replCoord);
}
首先,内部将会调用_syncTail负责整体管理数据的拉取和回放,其中拉取用到的callback就是getNextApplierBatch,我们先来看下这个函数,它将返回一批Batch oplog,并保证:
- 最多BatchLimits::ops个OplogEntries会被返回。
- 最多BatchLimits::bytes个byte会被返回。
- 返回的时间不会大于BatchLimits::slaveDelayLatestTimestamp时间点
- Op=c的话,返回只有1条,不能被group了。此外,发生在ns为system.view和admin.system.version也不能被group。大家可以思考一下这里为什么op=c不做group batch处理。
3.3 SyncTail::oplogApplication
SyncTail分两步处理:首先是创建ReplBatcher线程,然后是调用_oplogApplication。
ReplBatcher线程负责调用上面说的getNextApplierBatch从oplogBuffer里面拉取数据,并组织成OpQueue _ops;。另外内部还有一些状态判断,判断是否已经shutdown了;还有比如当前term内,oplogBuffer中的数据已经消耗完了等。
3.4 SyncTail::_oplogApplication写入batch数据
3.4.1 判断当前是否需要流控(4.2添加)
3.4.2 获取当前minValid位点
3.4.3 调用batcher->getNextBatch获取batch oplog
3.4.4 获得当前lastApplied位点
3.4.5 内部调用了SyncTail::multiApply进行多线程写入
其内部主要包括以下流程:
- 抢锁:pbwm(Lock::ParallelBatchWriterMode),保证加锁期间老的oplog不能被删除。
- oplog是按batch写入的,所以需要等待上一次的batch写入完成
- 设置truncateAfter位点为当前batch的第一条oplog的opTime
- 多线程分批次调用scheduleWritesToOplog写入oplog表,将会封装wiredTiger事务写入整批oplog。线程默认16个,但是如果线程不够用,写入线程将会动态调整,根据计算好的线程数对batch oplog进行分段切分,然后分段并发写入。
- 调用fillWriterVectors填充二维写数组writerVectors,对于wiredTiger来说,按_id进行hash以保证表内并发,但是同一个_id还是会保证有序。对于部分操作,由当前secondary生成伪操作(pseudo operations),这个不会复制给下游(当前步骤之前oplog已经写入完毕):1. 将applyOps操作分拆成单个独立的ops。这样做的好处是,secondary写入applyOps不需要加全局锁了。但是secondary上的oplog还是applyOps; 2.对于config.transactions的写入(事务),由于primary上config.transactions的写入不会产生oplog,而是一条假的oplog,所以需要对其进行解析并写入当前secondary。
- 等待上面第4步的oplog表的并发写入完成
- 设置truncateAfter位点为空,设置minValid位点为当前batch oplog的最后一条的opTime。如果节点挂了,则没必要清空truncateAfter后的oplog,同理,将会根据minValid位点进行恢复。
- 调用SyncTail::_applyOps多线程应用输入的operations,只会应用大于beginApplyingTimestamp的operation,如果小于则不会应用,但是oplog表还是会写入。其中负责写入真正写入的函数_applyFunc为multiSyncApply函数(这个函数内部细节下面介绍)。
- 等待所有线程应用完成,并判断是否存在失败。
- 调用storageEngine->replicationBatchIsComplete()更新存储引擎的视图。
- 更新写入的计数
- 返回最后一条oplog的时间戳
3.4.6 用batch oplog最后一条oplog的时间戳推进appliedThrough位点
3.4.7 获取lastApplied位点,并确保该位点在当前batch oplog同步完成之前没有被推进
3.4.8 _storageInterface->oplogDiskLocRegister告知wiredTiger当前写入的batch oplog可见
3.4.9 判断当前的位点(最后一条batch oplog时间戳)是否大于minValid,是的话consistency为true,否则为false。
3.4.10 调用finalizer->record推进时间戳
其内部依次调用了_recordApplied,ReplicationCoordinatorImpl::setMyLastAppliedOpTimeAndWallTimeForward以推进位点。
首先推进全局时钟。
然后判断输入的opTime时钟是否大于lastApplied位点,是的话则调用ReplicationCoordinatorImpl::_setMyLastAppliedOpTimeAndWallTime推进lastApplied位点:
- 先更新lastApplied位点
- 如果启用了write majority,并且没有启用j参数,则还会调用ReplicationCoordinatorImpl::_updateLastCommittedOpTimeAndWallTime推进lastCommit位点,以及调用ReplicationCoordinatorImpl::_setStableTimestampForStorage更新stableTimestampCandidate。
- 更新local snapshot
- 如果是一致的状态,则将当前时间戳写入_stableOpTimeCandidates 否则,如果节点的状态是STARTUP2,则推进节点的oldestTimestamp。
multiSyncApply写入单个batch的oplog的细节:
1. 将输入的一个batch按namespace排序
2. 调用InsertGroup::groupAndApplyInserts判断是否可以组成一个group,组成group的条件:
a) 必须为insert操作
b) 必须为同一个namespace
c) 插入的表不能为capped collection
d) group的大小不能超过kInsertGroupMaxBatchSize:256K
e) group的条数不能超过kInsertGroupMaxBatchCount:64
最后会调整写入的文档格式,从
a) { ts: Timestamp(1,1), t:1, ns: "test.foo", op:"i", o: {_id:1} }
b) { ts: Timestamp(1,2), t:1, ns: "test.foo", op:"i", o: {_id:2} }
聚合为一条文档:
{ ts: [Timestamp(1, 1), Timestamp(1, 2)],
t: [1, 1],
o: [{_id: 1}, {_id: 2}],
ns: "test.foo",
op: "i" }
3. 调用SyncTail::syncApply执行group(可以聚合,只有上面所说的insert可以聚合)或者单条(不能聚合)写入
a) 如果是noop,则忽略。
b) 如果是CRUD操作则采用applyOp回调函数执行写入,其将会对于非initSync阶段启用upsert,并且如果是RECOVERING和STARTUP阶段,会忽略upsert的报错。内部调用applyOperation_inlock执行真正的写入
c) 如果是DDL操作则调用applyCommand_inlock执行写入。
4. 几个位点的区别
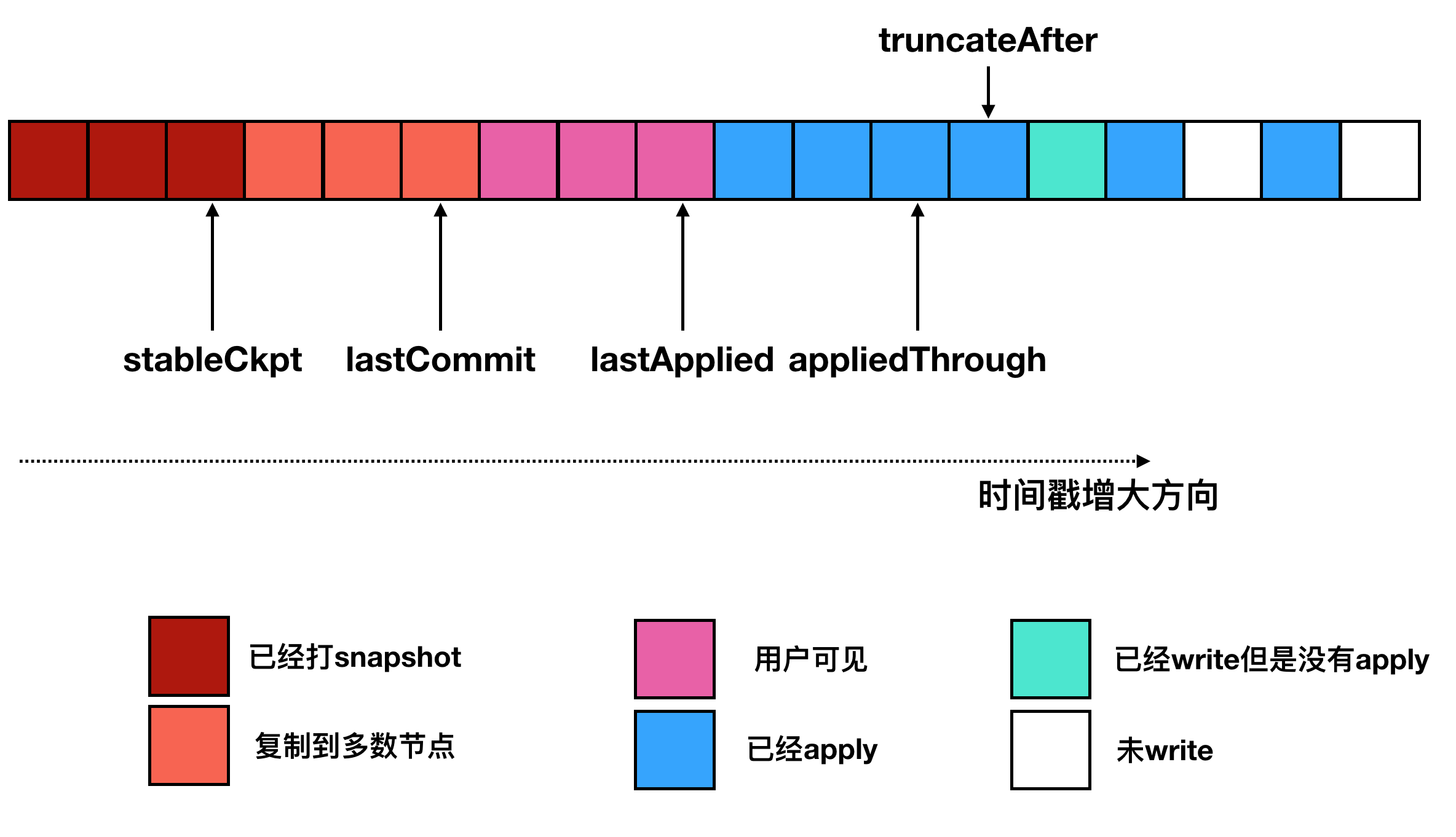
- stableCkpt:表示这个是wiredTiger做了的checkpoint。
- lastCommit:表示这个位点的数据已经复制到大多数节点。一旦回滚将会保证能回滚到lastCommit
- lastApplied:用于表示这个位点之前的都是可见的。推进在4.0以前是通过粗暴加锁实现的,4.0以后通过wiredTiger提供的多版本读能力实现的。
- appliedThrough:表示一批batch的并发回放结束,但不一定可见
- oplogTruncateAfterPoint:发生中断这个位点开始的后面oplog会被截断。
Q: 如何保证发生回滚,一定能回滚到lastCommit?
A: stableCkpt是一个全量的镜像,回滚将会加载这个镜像,stableCkpt到lastCommit是通过增量oplog进行恢复。也就是说通过全量+增量恢复到这个lastCommit位点。
Q: 并发写入的时候,是先write oplog还是先apply数据?
A: 先write oplog,然后再apply。如果重启将会把appliedThrough以后的oplog阶段掉重新应用。
说明:
转载请注明出错:http://vinllen.com/mongodbzhu-cong-fu-zhi-zhi-zeng-liang-tong-bu/
参考:
https://github.com/mongodb/mongo/blob/master/src/mongo/db/repl/README.md
https://www.percona.com/blog/2018/10/10/mongodb-replica-set-scenarios-and-internals/
https://yq.aliyun.com/articles/226367