
本文首先介绍一下混合逻辑时钟的基本概念,然后介绍MongoDB中的混合逻辑时钟是如何运用的。关于混合逻辑时钟的介绍大家可以参考http://vinllen.com/hun-he-luo-ji-shi-zhong/。
1. 逻辑时钟
逻辑时钟(LC)是由Lamport在time clock and the ordering of events in a distributed system这篇论文里面提出的,用于解决分布式场景下,时钟不一致无法定序的问题。其主要思想就是根据happened-before关系确定进程的逻辑时钟,从而确定进程的偏序关系:
- 如果a, b事件(消息)都是位于一个进程内(假设顺序发生,不考虑并发),且a位于b之前发生,那么a happened-before b, 记作:a hb b或者a->b,C(a)
- 如果a,b事件是位于2个进程内,a为消息的发送事件,b为同一个消息的接收事件。那么同样 a hb b。
Lamport的算法就是根据happened-before关系来确定逻辑时钟序的:
- 每个事件都有1个逻辑时间戳,初始为0。
- 如果事件发生在节点内部,则时间戳+1.
- 如果事件属于发送事件,则时间戳+1,并在发送的消息中携带时间戳。
- 如果事件属于接收事件,则时间戳=max{本地时间戳,消息中的时间戳}+1。
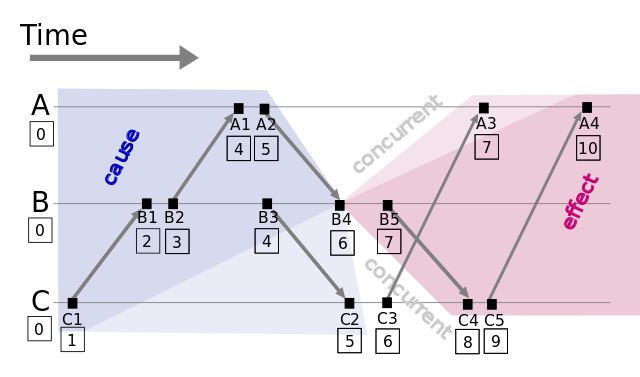
这样,通过该算法就确定了一个消息的偏序关系,比如上图中C1->B1, B1->B2, B2->A1。那么如何确定全序关系?通过给每个进程指定初始的优先级来确定,比如上图的A, B, C三个进程,我们分别指定A=1, B=2, C=3表示3个不同的序号,那么假设有2个相同的逻辑时钟C(B4)=C(C3),因为C=3>B=2,所以C(B4) 混合逻辑时钟(HLC)就是为了解决上面的前2个缺点,它具有以下几个特性: HLC捆绑了物理时钟跟逻辑时钟。一个时钟( 看到这里,大家对混合逻辑时钟应该有一个大概的印象了,下面是具体算法的细节。l和c表示高位的秒级时钟和低位的计数,j和m表示不同的进程,l'表示时钟发送变更后的l的值。所以l.j表示j进程的高位时钟,c.j表示j进程的低位计数,l'.j表示j进程的高位时钟变化后的值。 其核心思想就是我上面讲的更新算法。可以看到发送端或者发生在本地消息,都只触发tick,对于接收端,则比较源端时钟,源端大就用源端的,目的端大就用目的端的。最后结果都要tick一下。需要注意的是,发送端先自己tick以后,再把tick后的时钟携带发送。 图中pt代表机器的物理时钟, 算法到这就介绍完了,证明部分就不说了,可以看到混合逻辑时钟结合了物理时钟跟逻辑时钟,不仅可以满足happened-before关系,还可以根据物理时钟进行比较。 MongoDB在3.6版本推出混合逻辑时钟,对应的也就是ClusterTime,其由 但是MongoDB里面的混合逻辑时钟的推进机制跟原生混合逻辑时钟论文介绍有所不同,原生混合逻辑时钟论文介绍的混合逻辑时钟的推进是受消息的发送和接收触发的,而MongoDB里面推进只受primary节点的oplog产生而推进。啥意思呢?就是只有primary节点上有oplog产生,时钟才会向前推进,也就是MongoDB的状态发生了变更。所以读请求是不会造成时钟推进。 客户端本身也会存储服务端返回的clusterTime,每次发送的时候都会携带这个clusterTime发送,以推进时钟。例如下面这个例子: 客户端发送写请求的时候携带了clusterTime=T1,服务端收到以后,对其进行比较,其规则跟混合逻辑时钟介绍的一样,先跟本地对比,然后找出最大的进行tick到T2,然后写入到oplog(ts=T2),再回复给客户端,最后客户端更新本地的时钟到T2,用于下一次发送。 我们上面提到了,计数是32位的数字,正常情况下,我们知道计数值不会用尽,假设一秒100w的qps,最多也就用20位。但是假如是客户端恶意攻击,携带了最大的32位数字,那么服务端收到以后,一tick发现溢出了,就出问题了。那么如何避免这种情况?我们注意到,在上面举例中,我们看到了server给客户端的回复还有一个signature签名字段,这个签名只能由服务端颁布,采用的HMAC-SHA1加密。客户端收到后会伴随clusterTime一起存储,下一次发送一起携带。这样,如果客户端发送了clusterTime,大于服务端当前的时钟,那么服务端会根据签名字段进行校验,一旦发现不符合就拒绝掉。 假如某个mongod本机的墙上时钟改了,比如改成最大的32位数字,那么客户端接收后如果进行更新,就会把高位的时间戳字段推到最大,导致后续无法再增加了,c字段势必会耗尽。应对这种方式,MongoDB提供了一个配置参数:maxAcceptableLogicalClockDriftSecs,默认1年。如果推进前后两次的时钟差距大于这个阈值,就会更新失败。 如何实现read own writes?比如在primary上写数据,在secondary如何保证一定能够读取到?客户端可以携带afterClusterTime参数实现因果一致性: 写完primary返回的是T2,然后携带afterClsuterTime=T2去secondary上读,这样secondary会等到时间推进到T2才返回。 假如我先访问shardA,然后拿着shardA返回的时钟去shardB上查询,并携带afterClusterTime,但是shardB的时钟落后于shardA,怎么办? 答案就是shard靠noop推动,但是此时shardB上不会干等下一个Noop才会返回,而是会强制写一个noop,其内容有别于正常的"periodic noop": 之前介绍过,只有primary节点的写请求才会触发时钟的推进,所以以下我们所知道的定期信息交互并不会推动时钟: 但是,以下2种定期消息可以对齐mongos, mongod和cs的时钟: 此外,mongod的自身时钟推进是靠10s一次的noop,在没有写请求情况下,靠上面所说的定期机制对齐cs,再对齐mongos。如果没有上述的定期机制和写请求,那么一个mongod的时钟是不能跟别的mongod,mongos以及cs对齐的。 MongoDB的时钟是混合逻辑时钟,但是又不同于原生的混合逻辑时钟,把原来由消息触发时钟推进,改为由primary节点状态变更推进时钟,更加便于实现。 转载请注明出处:http://vinllen.com/mongodbli-mian-de-hun-he-luo-ji-shi-zhong/ https://dl.acm.org/doi/pdf/10.1145/3299869.3314049 缺点
2. 混合逻辑时钟
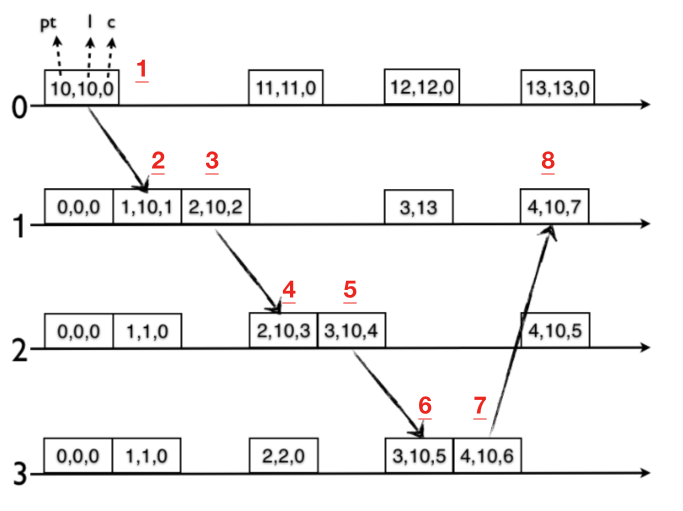
跟LC一样,消息的发送和接收将会触发时钟的推进。首先给出算法概述:对于发送端,触发消息的tick(下面会介绍什么是tick+1);对于接收端,如果发送的时钟大于本地,则采用发送端的时钟覆盖本地,否则采用本地的时钟进行tick。
so,到底什么是tick:拿高位时钟l跟本地的物理时钟pt对比,如果l>=pt,那么l不变,c+1;如果l<pt,那么l=pt,c=0。
举几个例子:

3. MongoDB中的混合逻辑时钟
{
"ts" : Timestamp(1571389994, 1), // 就是他!
"t" : NumberLong(1),
"v" : 2,
"op" : "i",
...
}
其他节点mongos,client并不会推进时钟,但是所有的角色(mongos,client,shard,cs)都会跟踪最新的时钟,并进行推进。那么如何跟踪这个时钟?答案就是消息的返回会携带一个$clusterTime字段,如果是写请求,那么客户端收到回复以后会进行存储,如果是读请求,则这个字段会被忽略:mongos> db.runCommand({"replSetGetStatus":1})
{
"info" : "mongos",
"ok" : 0,
"errmsg" : "replSetGetStatus is not supported through mongos",
"operationTime" : Timestamp(1585646540, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1585646540, 2), // 这个就是客户端返回的时钟
"signature" : { // 这个字段将在下面防止攻击用到
"hash" : BinData(0,"cp4aOXG5osJyXf7yibJtaL6m7sc="),
"keyId" : NumberLong("6791488152868487169")
}
}
}
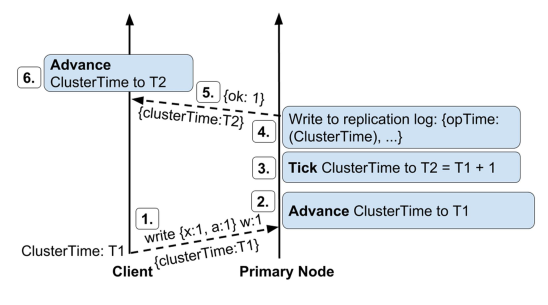
3.1 如何让客户端也统一时钟?
3.2 如何防止外部攻击
3.3 误操作问题,某个节点的墙上时钟推到最大
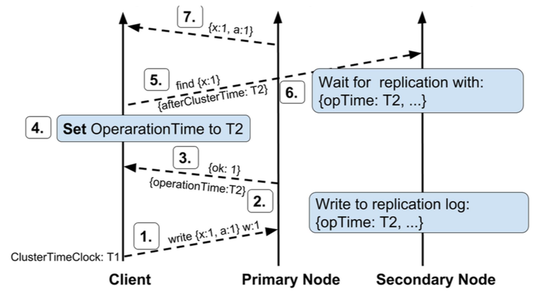
3.4 因果一致性
3.5 跨shard访问时钟不对齐怎么办?
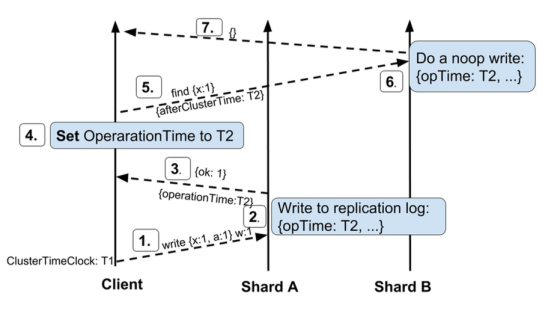
{
"ts" : Timestamp(1585831931, 1),
"t" : NumberLong(1),
"h" : NumberLong("-5745222443743484656"),
"v" : 2,
"op" : "n",
"ns" : "",
"wall" : ISODate("2020-04-02T12:52:11.791Z"),
"o" : {
"noop write for afterClusterTime read concern" : 1
}
}
3.6 在没有写请求的情况下,如何保证mongos, mongod, cs的时钟对齐?
a. mongos启动独立线程定期10s向cs的config.mongos表里插入一条ping数据,代码位于s/shardinguptimereporter.cpp/reportStatus函数,入口在ShardingUptimeReporter::startPeriodicThread。
b. mongos定期30s向cs的config.lockpings表里插入一条数据,代码位于ReplSetDistLockManager::doTask。
a. 同样,shard也会定期30s向cs的config.lockpings表里面插入一条数据,参见上面这个图。config.lockpings表是用于记录集群内各个角色存活状态的:
The lockpings collection keeps track of the active components in the sharded cluster. Given a cluster with a mongos running on example.com:30000, the document in the lockpings collection would resemble4. Q&A
A: 不能,客户端只能跟踪时钟,但是不能推进。
A: 不能,只有写请求才会推进时钟。
A: 不能,因为在没有写请求,mongos不会主动感知mongod的时钟推进了,除非是上述跟cs的定期机制。
A: 我认为是可能的,比如2个客户端通过2个不同的mongos写到2个shard里面,这样就是独立了。
A: fromMigrate是在shard上剔除的,排序是在mongos上做的,排序是按照ts+uuid+documentKey(shard key)来排的。如果有2个oplog时间戳ts一致,那么证明这2个oplog是并发的,那么只要既定策略就行,谁先谁后并不要紧。
A: 不能。因为混合逻辑时钟保证的是因果一致性,而Multi-master双向同步对于同一个key要求的是更为严格的一致性,比如是线性一致性,这个混合逻辑时钟不能满足需求。所以这种还是需要一个中心授时器。
5. 总结
说明
参考
http://vinllen.com/hun-he-luo-ji-shi-zhong/
https://cse.buffalo.edu/tech-reports/2014-04.pdf
https://docs.mongodb.com/manual/reference/command/replSetGetStatus/
https://docs.mongodb.com/manual/reference/bson-types/#document-bson-type-timestamp
http://www.mongoing.com/archives/25302
https://github.com/alibaba/MongoShake/issues/65