
sk_buff是Linux网络内核中最重要的数据结构之一。所有网络分层(MAC或L2分层上的另一种链路层协议,L3的IP,L4的TCP或UDP)都会使用这个结构来存储其报头,有关用户数据的信息,以及用来协调其工作的其他内部信息。当该结构从一个分层传到另一个分层时,其不同的字段会随之发生改变。在不同层数据传递时,通过附加报头的形式,减少了拷贝带来的开销。
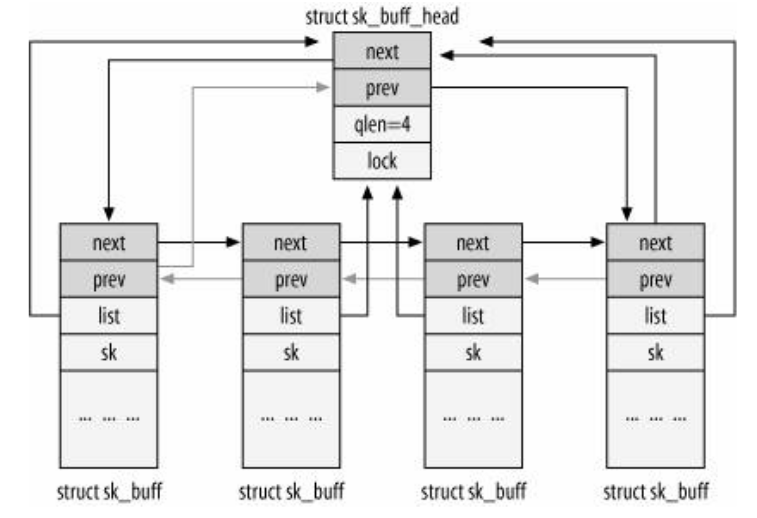
内核把所有sk_buff结构链成一个双向链表,并添加了一个头元素,该头元素的结构是sk_buff_head:
struct sk_buff_head {
struct sk_buff *next;指向后继结点
struct sk_buff *prev;指向前驱结点
__u32 qlen;表中元素的数目
spinlock_t lock;自旋锁,处理并发访问
}
由sk_buff结构链成的双向链表图:
本文将sk_buff分为以下四块内容进行介绍:
- 布局
- 通用
- 功能专用
- 管理函数
注:本文所说的缓冲区指的是sk_buff加上数据缓冲区。
1.布局字段
struct sk_buff *next;
struct sk_buff *prev;
分别表示前驱和后继结点。struct sock *sk;
指向拥有此缓冲区的套接字的sock数据结构。unsigned int len;
指缓冲区中数据区块的大小。这个长度包括主要缓冲区(由head所指)的数据以及一些片段的数据。len也会把报头算在内。unsigned int data_len;
只计算片段中的数据的大小。unsigned int mac_len;
MAC抱头的大小。atomic_users
使用当前sk_buff缓冲区的引用计数。为0才会释放。unsigned int truesize;
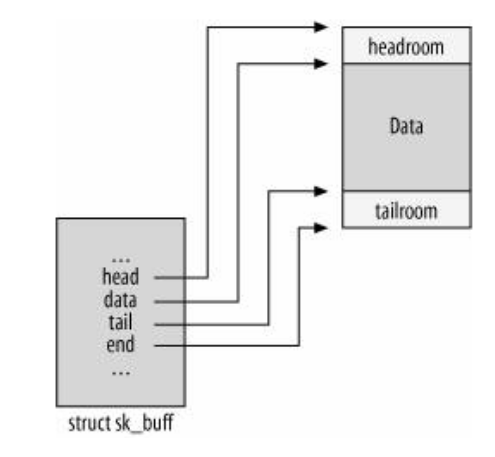
代表缓冲区的总大小,包括sk_buff结构本身。unsigned char *head;
unsigned char *end;
unsigned char *data;
unsigned char *tail;
指向缓冲区和数据的边界。head和end指向已分配缓冲区空间的开端和尾端。data和tail指向实际数据的开端和尾端。如图所示:
2.通用字段
本部分所包含的字段与特定内核功能无关:
struct timeval stamp;
时间戳,标记包何时被接收,或者有时用于表示封包预定传输的时间。struct net_device *dev;
标记接收和发送当前包的设备。struct net_device *input_dev;
发送当前所接收的包的源设备。主要由流量控制模块使用。struct net_device *real_dev;
如果接收是虚拟设备,则代表与虚拟设备所关联的真实设备。union {...} h
union {...} nh
union {...} mac
这些是指向TCP/IP协议报头的指针,h针对L4,nh针对L3,mac针对L2。例如,h是一个联合体,内核锁解释的每个L4协议的报头在h中都有一个字段。当接收一个数据包时,负责处理第n层报头的函数,会从第n-1层接收一个缓冲区,而该缓冲区的skb->data指向第n层报头的开端。处理第n层的函数会为该层初始化适当的指针(例如,L3的处理函数的skb->nh),用以保存skb->data字段,因为在下一层进行处理时,skb->data会设成缓冲区内另一个不同的偏移量,这个指针的内容就会丢失。此函数完成第n层的处理,把包传给第n+1层的处理函数前,先更新skb->data,使其指向第n层报头的尾端,也就是第n+1层报头的开始。见下图: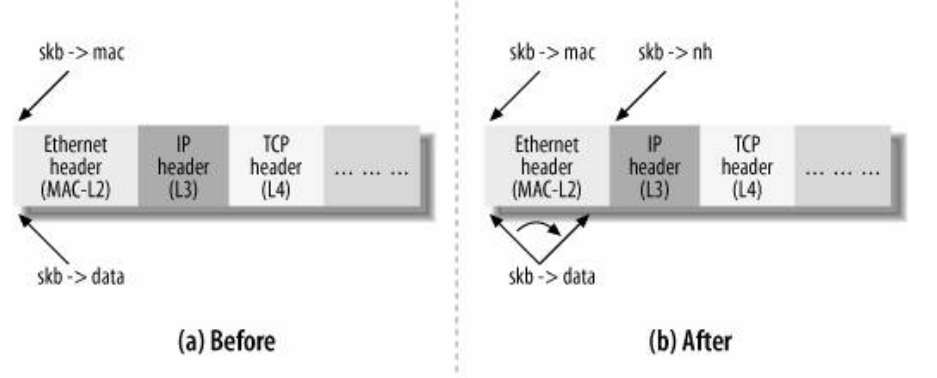
struct dst_entry dst;
用于路由子系统。char cb[40];
这是一个“控制缓冲区”,或者说是私有信息的存储空间,为每一层内部使用起维护的作用。该字段在sk_buff结构内静态分配,而且容量足以容纳每个层所需的私有数据。通过宏进行访问。例如:TCP使用这个空间存储一个tcp_skb_cb数据结构。那么访问该数据结构的宏如下:#define TCP_SKB_CB(_ _skb) ((struct tcp_skb_cb *)&((_ _skb)->cb[0]))unsigned int csum;
unsigned char ip_summed;
代表校验和以及相关联的状态标识。unsigned int cloned;
标记该sk_buff是否是另一个sk_buff缓冲区的克隆。unsigned char pkt_type;
此字段会根据帧的L2目的地址进行类型划分。__u32 priority;
表示正被传输或转发的包QoS等级。unsigned short protocol;
标识IP,IPv6以及ARP。unsigned short security;
包的安全级别。
3.功能专用字段
Linux内核是模块化的,允许加载/卸载模块。因此,只有当内核编译为支持特定功能,如防火墙或QoS,某些字段才会包含在sk_buff数据结构中:
unsigned int csum;
__u32 nfcache;
__u32 nfctinfo;
struct nf_conntrack *nfct;
unsigned int nfdebug;
struct nf_bridge_info *nf_bridge;
此部分参数由Netfilter使用。union {...} private;
此部分参数由HIPPI使用。__u32 tc_index;
__u32 tc_verd;
__u32 tc_classid;
此部分参数由流量控制功能使用。struct sec_path *sp;
此部分参数由IP协议组使用,记录转换信息。
4.管理函数
一般来说,内核中部分调用的函数有两部分格式:do_something和__do_something。前者是后者的包裹函数,处理参数检查,出错机制等。
分配内存:
alloc_skb和dev_alloc_skb
前者是分配缓冲区的主要函数,后者与前者不同的只是前者的包裹函数,为了优化的原因在申请的大小之上再加上16字节,用于中断模式下执行。建立一个缓冲区会涉及到两次内存分配:一个是分配数据缓冲区,而另一个是分配skb_buff结构。
alloc_skb通过调用kmem_cache_alloc函数,从一个缓存中取得sk_buff数据结构,然后调用kmalloc以取得一个数据缓冲区。如下图所示,其中SKB_DATA_ALIGN用于对齐,skb_shared_info块主要用于处理一些IP片段。
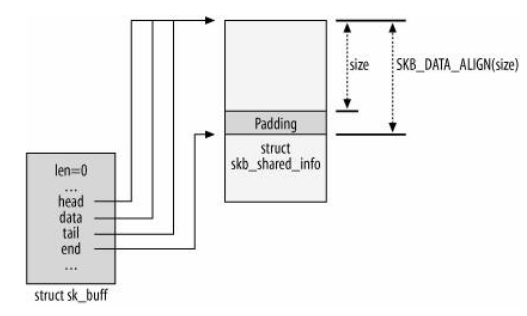
代码如下所示:skb = kmem_cache_alloc(skbuff_head_cache, gfp_mask & ~_ _GFP_DMA);
... ... ...
size = SKB_DATA_ALIGN(size);
data = kmalloc(size + sizeof(struct skb_shared_info), gfp_mask);释放内存:
kfree_skb和dev_kfree_skb
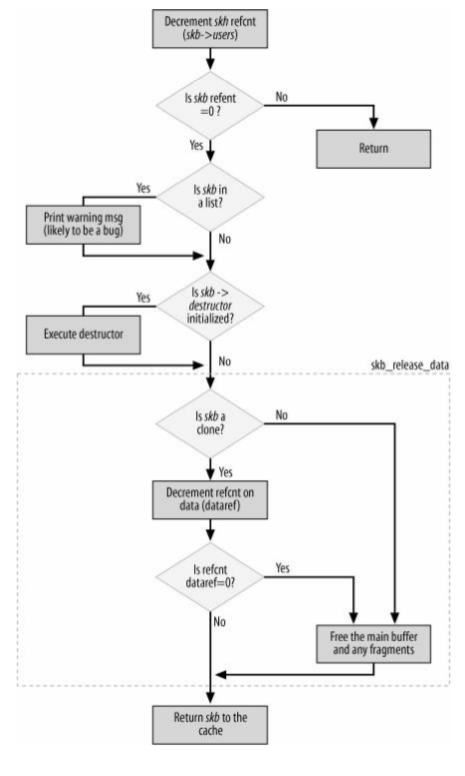
这两个函数会释放一个缓冲区,后者是前者的包裹函数。注意的是,释放时只有当skb->users计数器为1时,也就是该缓冲区没有其他任何用户时,才会释放一个缓冲区,否则只是递减计数器。kfree_skb主要流程如下:
- 数据预留及对齐:
skb_reserve,skb_put,skb_put,skb_push,skb_pull
这些函数都没有真的拷贝或者删除缓冲区,只是简单地移动其头尾指针。其主要操作如下图所示:
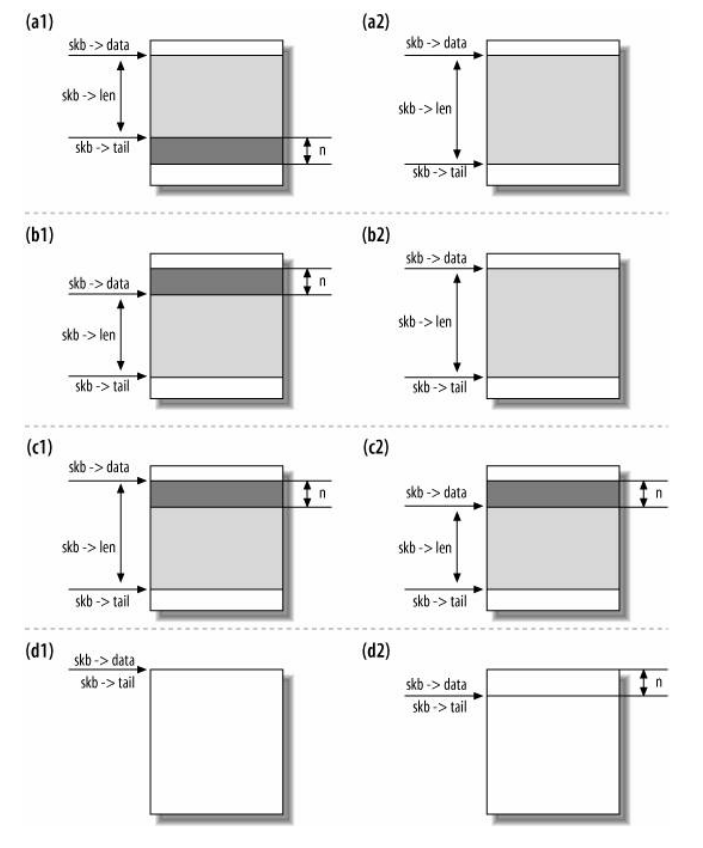
下图为更详细的skb_reserve调用,其中(a)表示在调用之前,(b)为调用之后,(c)为拷贝帧到缓冲区之后
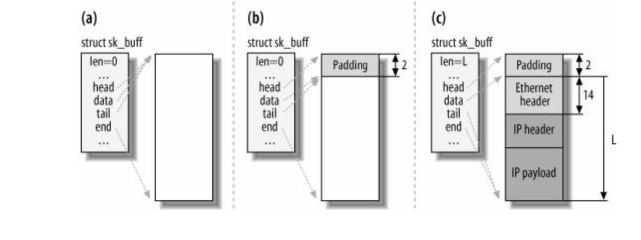
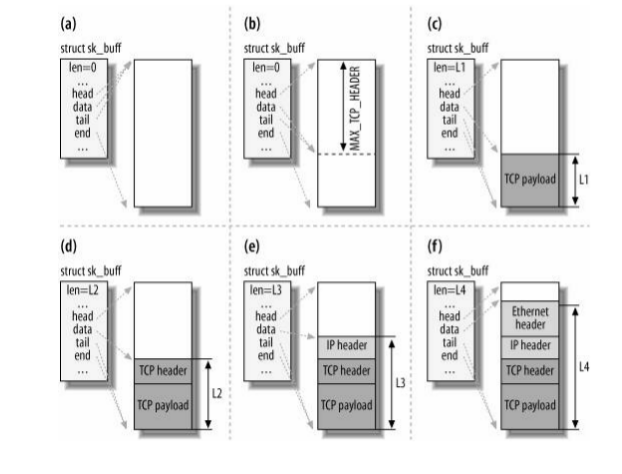
下图展示缓冲区穿过协议栈从TCP层传到链路层的过程:
skb_shared_info结构和skb_shinfo函数
skb_shared_info位于数据缓冲区的尾端,用以保持此数据区块的附加信息。由于sk_buff中没有指向skb_shared_info的字段,所以访问该结构的方式是使用skb_shinfo宏:#define skb_shinfo(SKB) ((struct skb_shared_info *)((SKB)->end))缓冲区的克隆和拷贝
当同一个缓冲区需要由不同消费者个别处理,且有可能修改sk_buff描述符的内容(指向协议报头的h和nh指针)时,内核不需要完全拷贝sk_buff结构和相关联的数据缓冲区。内核可以使用克隆实现,也就是拷贝sk_buff结构,然后使用引用计数。缓冲区的克隆由函数sk_clone实现。
克隆之后,skb->cloned字段在克隆和原有的缓冲区都为1,skb->users也为1,使得尝试修改直接成功,但是,对包含数据的缓冲区的引用书目(dataref)递增1次。如下图所示:
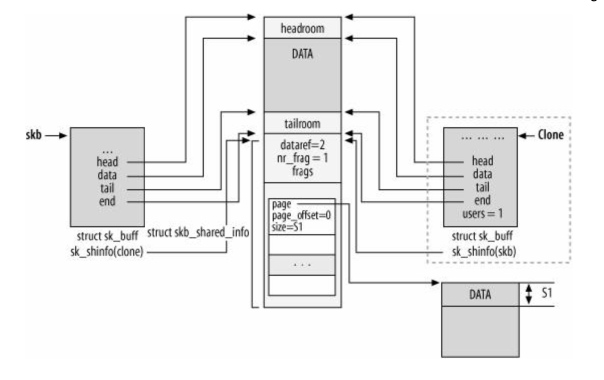
skb->cloned函数也可以检查一个skb缓冲区的克隆状态。
当一个缓冲区被克隆时,数据区块的内容不能修改。这意味着访问该数据的代码不需要上锁机制。然后,当函数不仅需要修改sk_buff结构的内容,而且也需要修改数据时,就必须连数据区块一起克隆。在这种情况下,有两种选择:当知道只需修改介于skb->start和skb->end的区域的数据内容时,可以使用pskb_copy只克隆该区域;当认为可能必须连片段数据区块的内容也会修改,就必须使用skb_copy。这两个函数如下图所示:
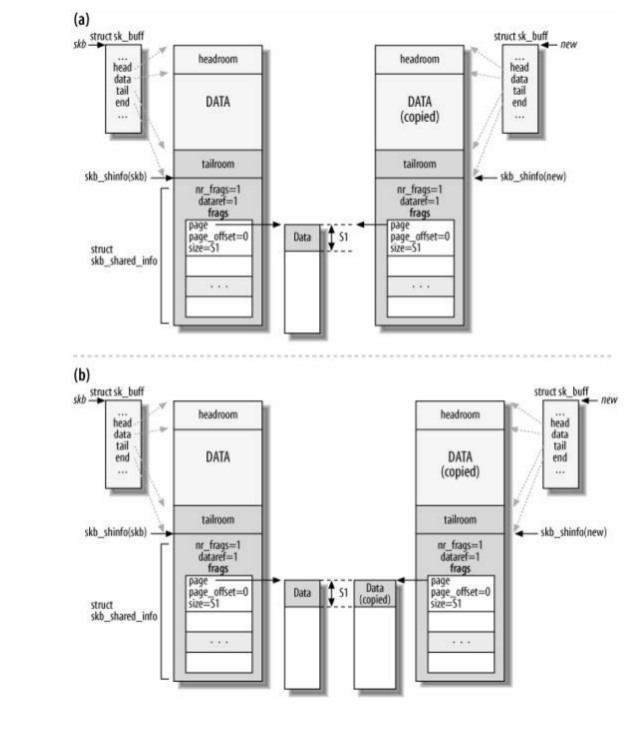
- 链表管理函数
以下这些函数用于操作sk_buff链表,足以这类函数都必须以原子方式执行,所以需要提供自旋锁。
skb_queue_head_init//用于初始化链表。
skb_queue_head和skb_queue_tail//用于把一个缓冲区添加到头部和尾部。
skb_dequeue和skb_dequeue_tail//用于在头部和尾部删除一个缓冲区。
skb_queue_purge//清空链表。
skb_queue_walk//遍历链表。
//每个函数按照以下方式运行:static inline function_name ( parameter_list )
{
unsigned long flags;
spin_lock_irqsave(...);
_ _ _function_name ( parameter_list )
spin_unlock_irqrestore(...);
}