
在内核中分配内存空间不像在其他地方分配内存这么容易,主要原因是空间受限。内核与用户空间不同,不支持这种简单便捷的内存分配方式。
1.页
内核把物理页作为内存管理的基本单位。尽管处理器的最小可寻址单位是字,但内存管理单元(MMU)通常以页为单位进行处理,大多数32位体系结构支持4KB的页,64位为8KB。内核用struct page结构体表示系统中的每个物理页。
struct page {
unsigned long flags; //页状态,标识是否为脏页,是否锁定在内存等等。一共有32位标识
atomic_t _count; //该物理页的引用次数
atomic_t _mapcount;
unsigned long private;
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
void *virtual; //页的虚拟地址
}
内核用这一结构体来管理系统中所有的页,因为内核需要知道一个页是否空闲(也就是页有没有被分配)。如果页已经被分配,需要知道拥有者。这个数据结构描述了当前相关的物理页中存放的东西,目的在于描述物理内存本身,而不是描述包含在其中的数据。
2.区
有些页位于内存中特定的物理地址上,所以不能将其用于一些特定的任务,因此内核把页划分为不同的区(zone),内核使用区对具有相似特性的页进行分组。Linux必须处理如下两种由于硬件存在缺陷而引起的内存寻址问题:
- 一些硬件只能用某些特定的内存地址来执行DMA(直接内存访问)。
- 一些体系结构的内存的物理寻址范围比虚拟寻址范围大得多。这样,就有一些内存不能永久地映射到内核空间上。
因为存在以上制约,Linux主要使用了4种区:
ZONE_DMA:这个区包含的页能用来执行DMA操作。ZONE_DMA32:和ZONE_DMA类似,该区包含的页面可用来执行DMA操作,不同在于,这些页面只能被32位设备访问。ZONE_NORMAL:这个区包含的都是能正常映射的页。ZONE_HIGHEM:这个区包含"高端内存",其中的页并不难永久映射到内核地址空间。
在x86体系结构中,ISA设备就不能在整个32位地址空间执行DMA,因为ISA设备只能访问物理内存的前16MB。因此,ZONE_DMA在x86上包含的页都在0-16MB的内存范围内。下图是每个区及其在x86-32上所占页的列表。

3.获得页
页分配方式如下:
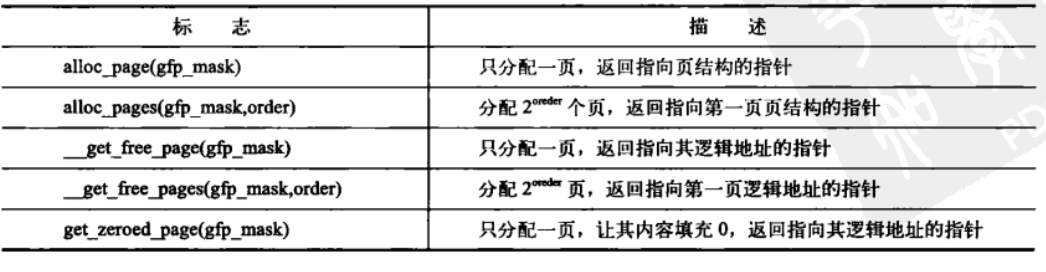
页释放可以用__free_pages,free_pages和free_page。
4.kmalloc
kmalloc用来获得以字节为单位的一块内核内存。其定义如下:
void *kmalloc(size_t size, gfp_t flags);
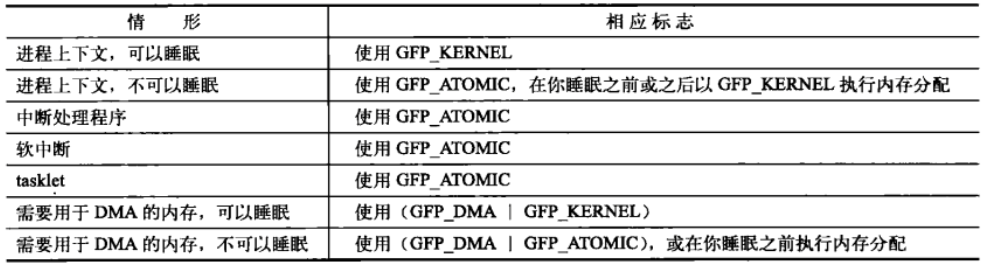
其中的flags为分配器标志。这些标志可以分为三类:
- 行为修饰符。表示内核应当如何分配所需的内存。在某些特殊情况下,只能试用某些特定的方法分配内存。见下图:


- 区修饰符。指明到底从这些区忠的哪一个区中进行分配。见下图:

- 类型标志。组合了行为修饰符和区修饰符,将各种可能用到的组合归纳为不同类型,简化了修饰符的使用;这样,只需制定一个类型标志就可以了。

下表显示了在每种类型标志后隐含的修饰符列表。

下表显示了什么时候用哪种标志。
kfree用于释放由kmalloc分配出来的内存块。
5.vmalloc
kmalloc确保页在物理地址上和虚拟地址上都是连续的,而vmalloc只确保虚拟地址上的连续。vmalloc为了把物理上不连续的页转换为虚拟地址上连续的页,必须专门建立页表项。糟糕的是通过vmalloc获得的页必须一个一个进行映射(因为他们物理上是不连续的),这就会导致比直接内存映射大得多的TLB抖动。所以,vmalloc仅在不得已时才会使用--典型的就是为了获得大块内存时,例如,当模块被动态插入到内核中时,就把模块装载到由vmalloc分配的内存上。
同样,vfree用于释放由vmalloc分配出来的内存块。
6.slab层
为了便于内存中数据的频繁分配和回收,编程人员通常会用到空闲链表。其包含可供使用的,已经分配好的数据结构块。当代吗需要一个新的数据结构实例时,就可以从空闲链表中抓取一个,而不需要分配内存,再把数据放进去;当不需要这个数据结构时,就把它放回空闲链表,而不是释放。从这个意义上说,空闲链表相当于对象高速缓存--快速存储频繁使用的对象类型。
在内核中,空闲链表面临的主要问题之一是不能全局控制。当可用内存变得紧缺时,内核无法通知每个空闲链表,让其收缩缓存的大小以便释放一些内存。实际上,内核根本不知道存在任何空闲链表。为了弥补这一缺陷,Linux内核提供了slab层,它扮演了通用数据结构缓存层的角色。
slab层把不同的对象划分为所谓的告诉缓存组,其中每个高速缓存组都存放不同类型的对象。每种对象类型对应一个高速缓存。例如,一个高速缓存用于存放进程描述符(task_struct),另一个高速缓存存放索引节点对象(struct inode)。有趣的是,kmalloc接口建立在slab层之上,使用了一组通用高速缓存。
这些高速缓存又被划分为slab。slab由一个或多个物理上连续的页组成,一般情况下,slab也就仅仅一个页,每个高速缓存可以由多个slab组成。每个slab都包含一些对象成员,这里的对象指的是被缓存的数据结构。每个slab处于三种状态:满,部分满,空。当内核的某一部分需要一个新的对象时候,先从部分满的slab中进行分配,然后是空得。这种策略能减少碎片。
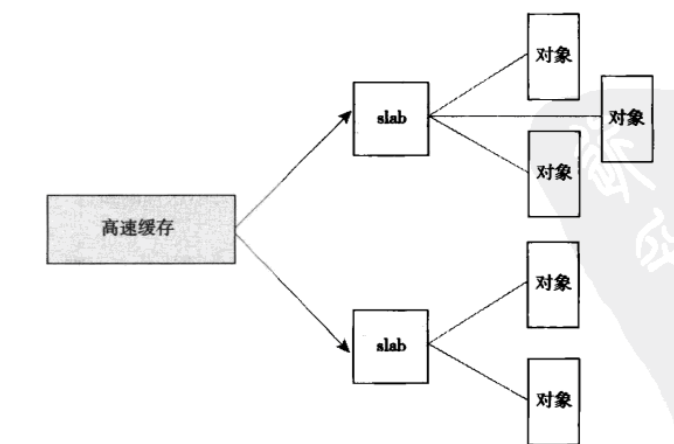
每个高速缓存都使用kmem_cache结构来表示,包含三个链表:slabs_full,slabs_partial,slabs_empty,均放在kmem_lists3结构体内。
7.在栈上的静态分配
内核栈小而且固定,不像用户栈一样大而且可以动态增长。每个进程的内存栈大小既依赖于体系结构,也与编译时的选项有关。历史上,每个进程都有两页的内核栈。
在2.6内核早期,引入了一个选项设置单页内核栈。单页内核栈好处在于:1.可以让每个进程减少内存消耗;2.随着机器运行时间的正价,寻找两个未分配的,连续的页变得比较困难,物理内存渐渐变为碎片;3.如果使用一个页面,中断处理程序不再像以前一样存放在内核栈中,而是开发了一个中断栈。中断栈为每个进程提供一个用于中断处理程序的栈,中断处理程序不再和被中断进程共享一个内核栈,他们可以使用自己的栈。对于每个进程来说仅仅耗费了一个页而已。
需要注意的是栈溢出会导致比较严重的后果,因为内核没有在管理内核栈上做足工作,因此,多余数据溢出会覆盖掉紧邻堆栈末端的东西。首先是thread_info结构。所以大量静态数据分配是很危险地,动态分配是比较明智的选择。
8.高端内存的映射
根据定义,在高端内存中的页不能永久地映射到内核地址空间上。因此,通过alloc_pages()函数以__GFP_HIGHMEM标志获得的页不可能有逻辑地址。需要通过映射才能解决。kmap可以用于永久映射,而kmap_atoic用于临时映射。
9.perCPU
每个cpu的数据存放在一个数组中,数据中的每一项对应着系统上一个存在的处理器。perCPU的好处在于:
- 减少了数据锁定。按照每个处理器访问每个cpu数据的逻辑,可以不再需要任何锁。
- 使用每个cpu数据可以大大减少缓存失效。
使用每个cpu数据会省去许多数据上锁,它唯一的安全要求就是要禁止内核抢占。需要注意的是,不能在访问perCPU数据过程中睡眠--否则,你就可能醒来后已经到其他处理器上了。
10.总结
如果需要连续的物理页,就可以使用某个低级页分配器或kmalloc。如果想从高端内存进行分配,就是用alloc_pages,其返回一个指向struct page结构的指针,而不是一个指向某个逻辑地址的指针。如果不需要物理上连续的页,而仅仅是虚拟地址上连续的页,可以用vmalloc,不过其相对kmalloc有一定的性能损失。如果要创建和撤销很多大的数据结构,考虑建立slab高速缓存。
参考
《Linux内核设计与实现》