
本文将首先依次简单介绍分布式系统下的物理时钟(Physical Time,也称PT),逻辑时钟(Logical Clock,也称LC),向量时钟(Vector Clock,也称VC),真实时钟(True Time,也称TT)的基本概念,然后着重笔墨介绍混合逻辑时钟(Hybrid Logical Clock,也称HLC),论文来自Logical Physical Clocks
and Consistent Snapshots in Globally Distributed Databases。
说明:本文描述的时间戳和时钟是一个概念。
1. 物理时钟-Physical Time, PT
物理时钟即机器本地的时钟,而由于设备硬件不同,本身存在偏差,一天的误差可能有毫秒甚至秒级,所以需要对不同的机器时钟进行同步使得机器的时间进行相对统一。NTP是目前比较常用的同步时间的方式,其机制为CS架构,每台机器上存在一个NTP的客户端,与NTP的服务端进行同步,校准本地的时间。关于NTP具体的设计细节本文不做详细介绍,需要知道的是,由于NTP走网络传输,势必会导致同步后的物理时钟与远程NTP服务器的时钟存在一定的偏差。
2. 逻辑时钟-Logical Clock, LC
由于在分布式场景下,不同机器的时间可能存在不一致,那么就没办法对跨节点的事件确定的先后关系。所以Lamport推出了逻辑时钟的概念,通过happened-before关系确定事件的逻辑时钟,从而确定事件的偏序关系。
那什么是happened-before关系?
- 如果a, b事件都是位于一个进程内(假设顺序发生,不考虑并发),且a位于b之前发生,那么a happened-before b, 记作:
a hb b或者a->b,C(a)<C(b),C表示逻辑时钟。 - 如果a,b事件是位于2个进程内,a为消息的发送事件,b为同一个消息的接收事件。那么同样
a hb b。
Lamport的算法就是根据happened-before关系来确定逻辑时钟序的。
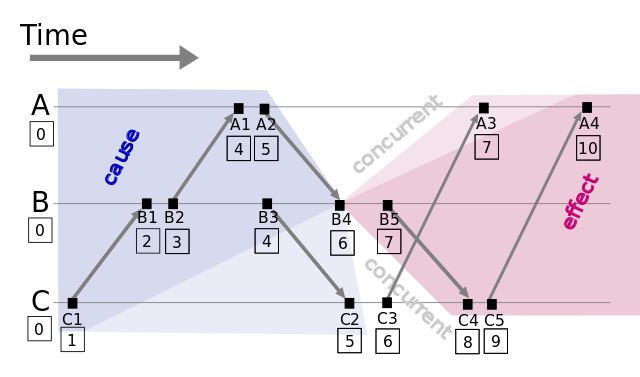
- 每个事件都有1个逻辑时间戳,初始为0。
- 如果事件发生在节点内部,则时间戳+1.
- 如果事件属于发送事件,则时间戳+1,并在发送的消息中携带时间戳。
- 如果事件属于接收事件,则时间戳=max{本地时间戳,消息中的时间戳}+1。
这样,通过该算法就确定了一个消息的偏序关系,比如上图中C1->B1, B1->B2, B2->A1。那么如何确定全序关系?通过给每个进程指定初始的优先级来确定,比如上图的A, B, C三个进程,我们分别指定A=1, B=2, C=3表示3个不同的序号,那么假设有2个相同的逻辑时钟C(B4)=C(C3),因为C=3>B=2,所以C(B4)<C(C3)。通过这种实现定序的方式,可以对所有事件排序,得到全序关系。
3. 向量时钟-Vector Clock, VC
LC能够保证a->b=>C(a)<C(b)(=>表示推导),但是不能通过C(a)和C(b)的大小推出a, b事件发生的先后顺序。
向量时钟是1988年,基于逻辑时钟提出的一个向量化的逻辑时钟,可以保证由C(a)<C(b)=>a->b。其由一个向量构成,向量的每个元素即是一个逻辑时钟,也叫做版本号,向量的维度等于节点个数,每个结点通过不同维度的版本号握有全局信息。向量属性如下:
- VCi[i]表示进程i上面事件发生的个数。
- VCi[j]表示进程i知道的j进程上面发生的事件发生数,即进程i对进程j的认知。
向量更新算法:
- 进程i每次发生1个事件,对VCi[i]+1
- 当进程i发送消息给进程j时,携带进程i的信息VCi整个向量时钟(进程i对全局的认知)。
- 当进程j收到进程i时,更新自己的VCj[k]=max{VCi[k], VCj[k]}, k从1-n,即向量内部所有维度都需要更新。
3.1 VC举例
比如同样上面的例子,有a, b, c三个机器,那么就有三个向量维度。
初始状态下每个维度状态都是0:
- VCa: [0, 0, 0]
- VCb: [0, 0, 0]
- VCc: [0, 0, 0]
a发生了1个事件,向量时钟更新:
- VCa: [1, 0, 0]
- VCb: [0, 0, 0]
- VCc: [0, 0, 0]
过段时间b和c收到来自a的更新,更新本地向量时钟:
- VCa: [1, 0, 0]
- VCb: [1, 0, 0]
- VCc: [1, 0, 0]
同一段时间内,b发生2次事件,更新本地向量时钟:
- VCa: [1, 0, 0]
- VCb: [1, 2, 0]
- VCc: [1, 0, 0]
同样,过段时间a和c收到来自b的更新,更新本地向量时钟:
- VCa: [1, 2, 0]
- VCb: [1, 2, 0]
- VCc: [1, 2, 0]
向量时钟更新存在一个问题,加入两端同时更新,那么最后应该采用哪个结果,比如b更新为[1, 3, 0], c更新为[1, 2, 1],那么b和c该如何合并?VC只发现冲突,并不处理,具体的处理方式可以有多种,比如交由客户端进行处理合并、最后一个更新生效(last write win)等。
4. 真实时钟-True Time, TT
TT包括一个时间戳t,还有一个误差e(e通常稳定在4ms以内,误差为[-e, +e])。其实现的基础是基于GPS和原子钟。之所以采用2种技术是为了保证精确度。GPS有一个天线,电波干扰会导致失灵。而原子钟比较稳定,当GPS失灵的时候,原子钟仍然能够保证在一段相当长的时间内,不会出现偏差。
每个数据中心需要部署一些主时钟服务器(Master),其他机器上部署一个从时钟进程(Slave)来从Master进行时钟同步。Master可以采用GPS或者原子钟的方式。Slave定期30s从若干个Master同步时钟信息。
Google Spanner使用了一种延迟提交(Commit Wait)的手段,即如果事务T1的提交版本为时间戳t那么事务T1会在t+e之后才能提交。借用这种方式消除误差e带来的影响,从而保证线性一致性。这种方式的缺点是,事务的提交需要延迟等待,这为系统的性能带来了影响,比如e, g事务有happened-before关系,那么e的延迟提交将导致f被delay;另外,原子钟的实现代价非常高昂。
5. 混合逻辑时钟-Hybrid Logical Clock, HLC
刚才我在介绍向量时钟时讲过逻辑时钟的缺点:不能通过C(a)和C(b)的大小推出a, b事件发生的先后顺序。这个会在使用时导致很多困扰,比如一个外部系统在一个逻辑时钟的分布式系统下的2个进程内部先后提交了互不相关的2个事务:e和f,f在e之后再提交。那么理论上应该e先完成,然后再f,但在逻辑时钟视角下,可能f在e之前先完成了。这个问题有几种解决方式,1种是将这个外部系统划入当前分布式系统内,但你不可能杜绝外部系统的调用;另外就是让逻辑时钟和物理时钟达成一致,这个比较困难,混合逻辑时钟HLC就是一种“尽可能”的方式。
混合逻辑时钟是2014年提出的,混合了物理时钟PT和逻辑时钟LC。其推出的目标是为了实现以下4个目标:
- 满足LC的因果一致性happened-before。
- 单个时钟O(1)的存储空间(VC是O(n),n为分布式系统下的节点个数)。
- 单个时钟的大小有确定的边界(不会无穷大)。
- 尽可能接近物理时钟PT,也就是说,HLC和PT的差值有个确定的边界。这条规则的好处是,只要两次操作间隔大于这个确定的边界,就可以保证因果一致性,无论是否是当前分布式系统内的。
混合逻辑时钟一共64位,高32位是秒级时间戳,低32位是计数。
5.1 一种朴素的算法(非最优)
作者一开始抛出了一种朴素的算法,如下图所示,论文中其中j, m表示事件,lc、pt、hlc分别对应上面说的逻辑时钟、物理时钟和混合逻辑时钟,比如lc.j表示逻辑时钟表示的j事件的时间戳。l一般表示当前算法。

这个想法比较简单,发送根据上一次的l.j+1和pt.j时间戳更新本地;接收时根据本地的l.j+1, 消息的l.m+1,pt.j三者最大值进行更新。粗看起来这种想法即能够满足lc的因果一致性,又能够结合PT。但这个并不能满足上述规则的第4条:HLC和PT的差值有个确定的边界,比如下面这个例子。
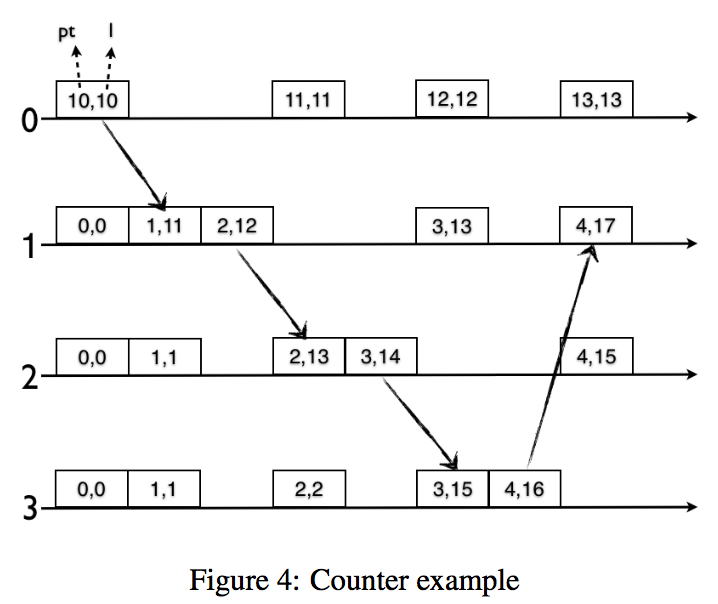
在进程0的时候,pt=10, l=10(l这里就是当前朴素的hlc),更新到进程1是l=11,因为本地pt比较落后(或者说进程0的比较靠前),进程1进行一次更新变成l=12,同理一直到进程2,然后到进程3,最后再回到进程1,我们发现这个时候l=17了,但是进程1的pt才只有4,这是因为消息传递很快,远快于pt的更新时间,所以会导致pt和l的差值不能稳定在一个确定的边界,也就违背了规则4。从一定意义上来说,这种算法也已经退化成LC了。
5.2 改进后的算法
作者将hlc的时间戳拆成2部分:物理时钟pt(用l表示)和计数c,作者的建议是采用64位时间戳,高48位表示物理时钟pt,可以兼容于NTP时间,由于NTP只需要32位就可以表示秒级时间戳,所以48位可以表示更细粒度的时间戳,pt后面的c一共16位表示计数值,每次传递消息c要么+1,要么置0。下面给出具体的算法细节。

发送时候,本地时间戳l的更新规则:l.j=max{上一次l.j,本地pt.j},那么如果l等于上一个l的值,那么c+1(说明pt落后于hlc),否则l=pt,并置c=0(说明pt赶上了hlc)。接收的时候,先置l.j=max{上一次l.j,消息中的l,本地pt},如果等于本地l,说明pt没追赶上,计数c+1;如果等于l.m,说明m的时间戳比较大,则计数置为c.m+1;如果即等于本地l又等于pt,说明此时l和pt一样,那么c就取max{c.j, c.m}+1;如果都不满足,则说明pt已经追赶上,则置c=0。此处我说的可能有点绕,看下上面这个图就能看懂。
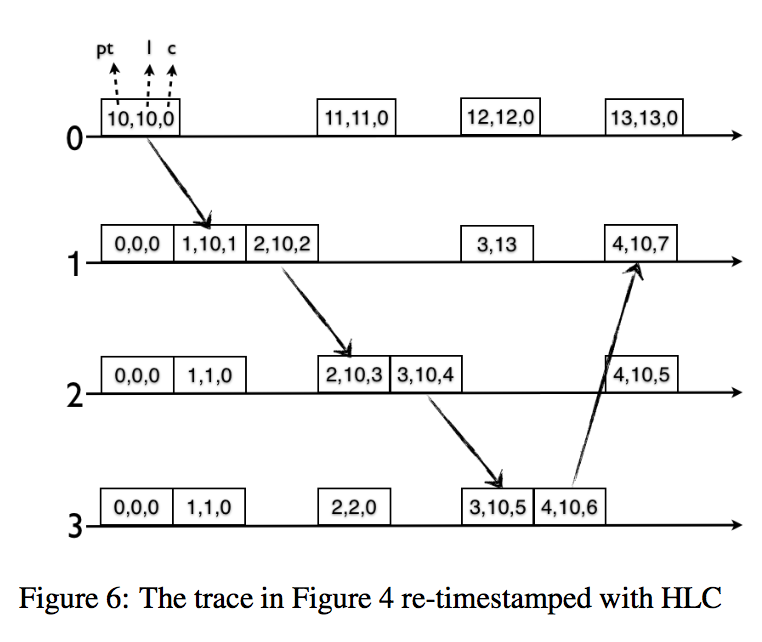
上面这个图给出了时间戳随着数据流的变更情况,不过这个给的并不是很好,并没有一定意义上说明|pt-hlc|是确界。
5.3 证明
紧接着,作者给定了一些证明说明这个算法分别满足开头我们说的4条规则。此处不做详细介绍。
5.4 实验
在实验部分,作者首先给定了一个实验,介绍在不同NTP同步时间间隔下,c的值以及l-pt的差值的变化。
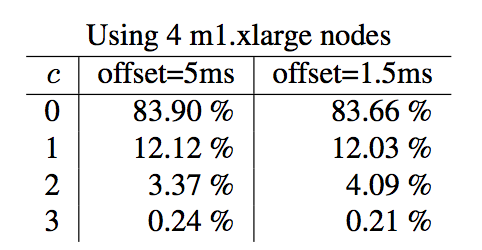
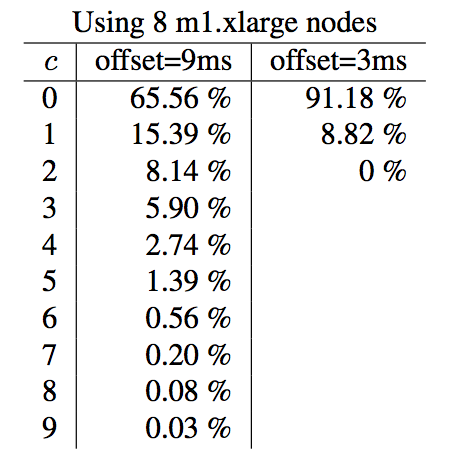
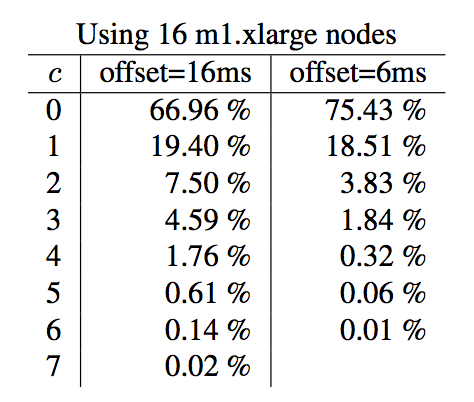
这3个图分别说明了在4,8,16个节点情况下,不同offset(offset表示NTP的更新时间)下,c值的变更情况,百分比说明c为当前值的概率,比如node=4, c=0在offset=5ms的概率是83.90%。其实我感觉这个实验做的也不好,并没有控制变量法,比如三组实验,offset值应该一样,这样能进行横向和纵向的对比。
下面还给出了这三组试验下,hlc和pt的差值分布。
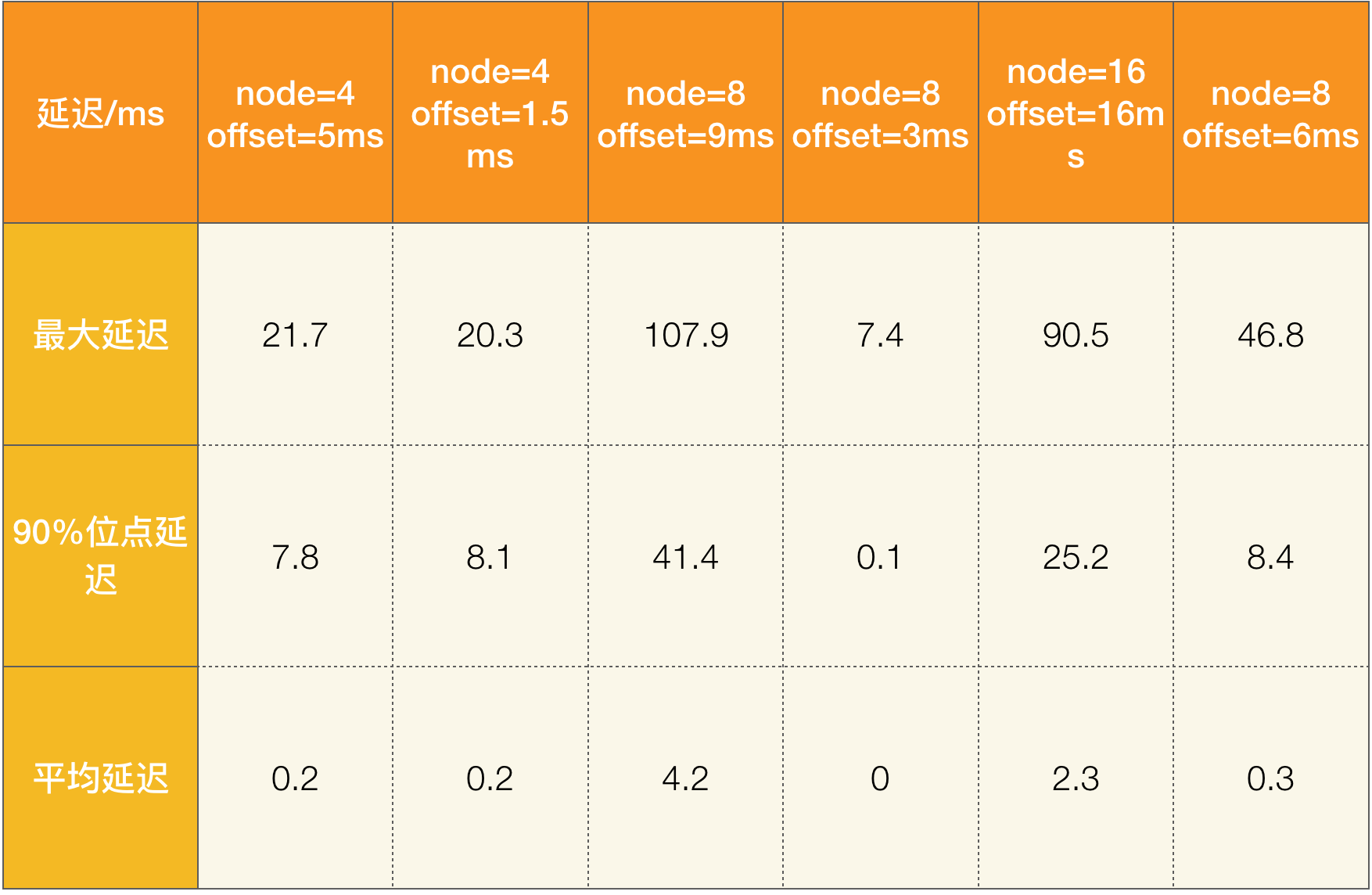
上面这个是同个数据中心内部的情况。另外,用户还给了个对比,当采用WAN全球部署网络的时候,c的值以及hlc和pt差值非常低,这是因为在网络延迟大的时候,通常时间戳的更新很及时,而c的值更新频率比较低,hlc和pt差值也很低。
由于c值通常不会太大,这也是作者开头介绍的l需要48位,而c只要16位就够了的原因。如果c的值超过了上限,或者hlc和pt的差值超过了一定的阈值,作者建议报警运维介入进行解决,但通常这种情况不会发生。
5.5 一致性快照
作者给出了一个一致性快照的例子<l=10,c=0>,表明HLC可以取到一致性快照(consistent snapshot)。

说明
转载请注明出处:http://vinllen.com/hun-he-luo-ji-shi-zhong/
参考
http://59.80.44.47/www.cs.sfu.ca/~vaughan/teaching/431.2009-3/papers/lamport78.pdf
https://cse.buffalo.edu/tech-reports/2014-04.pdf
http://blog.chinaunix.net/uid-27105712-id-5612512.html
https://blog.csdn.net/dongdong12345678900/article/details/86570457
http://www.cnblogs.com/ningskyer/articles/7446273.html
https://www.cnblogs.com/bangerlee/p/5448766.html
https://baike.baidu.com/item/%E5%81%8F%E5%BA%8F%E5%85%B3%E7%B3%BB/943166?fr=aladdin&fromid=2439087&fromtitle=%E5%81%8F%E5%BA%8F
https://baike.baidu.com/item/%E5%85%A8%E5%BA%8F%E5%85%B3%E7%B3%BB/943310?fr=aladdin
《大规模分布式存储系统》