
AWS Aurora笔记
写在前面:写一篇好的文章对精力、时间、知识的深入度等各方面要求都很高,所以我还是选择放弃了,简单记一下笔记,方便自己回忆吧。文章写于论文刚读完,所以可能很多理解不到位。
Aurora相对于社区版的MySQL解决的最主要的问题是什么,我认为就是IO,包括本地磁盘的随机IO和网络传输的IO。正如论文介绍的,the log is the database, Aurora整体都是基于这个log展开的。Aurora的几个优点:
- Aurora的复制同步成本低,只需要同步log,不需要同步page。
- 同步延迟低,相对于MySQL主从同步复制的master本地提交+slave提交的才返回的策略,Aurora是只要log写成功(落盘)即可,所有其他比如内存apply,不同存储节点追一致都是一个异步的策略。
- 脏页不需要写出到磁盘,内存不够直接换出。降低本地IO的随机写。
- 可用性高。能够应对多个节点挂掉还能提供读写服务的情况。
- checkpoint对用户影响低。
- 备份和恢复更加方便。
1. 集群设计
Aurora基本架构就是当下经典的计算层和存储层分离,最底下基于AWS S3的块存储底座。计算层和存储层的数据同步通过log实现。
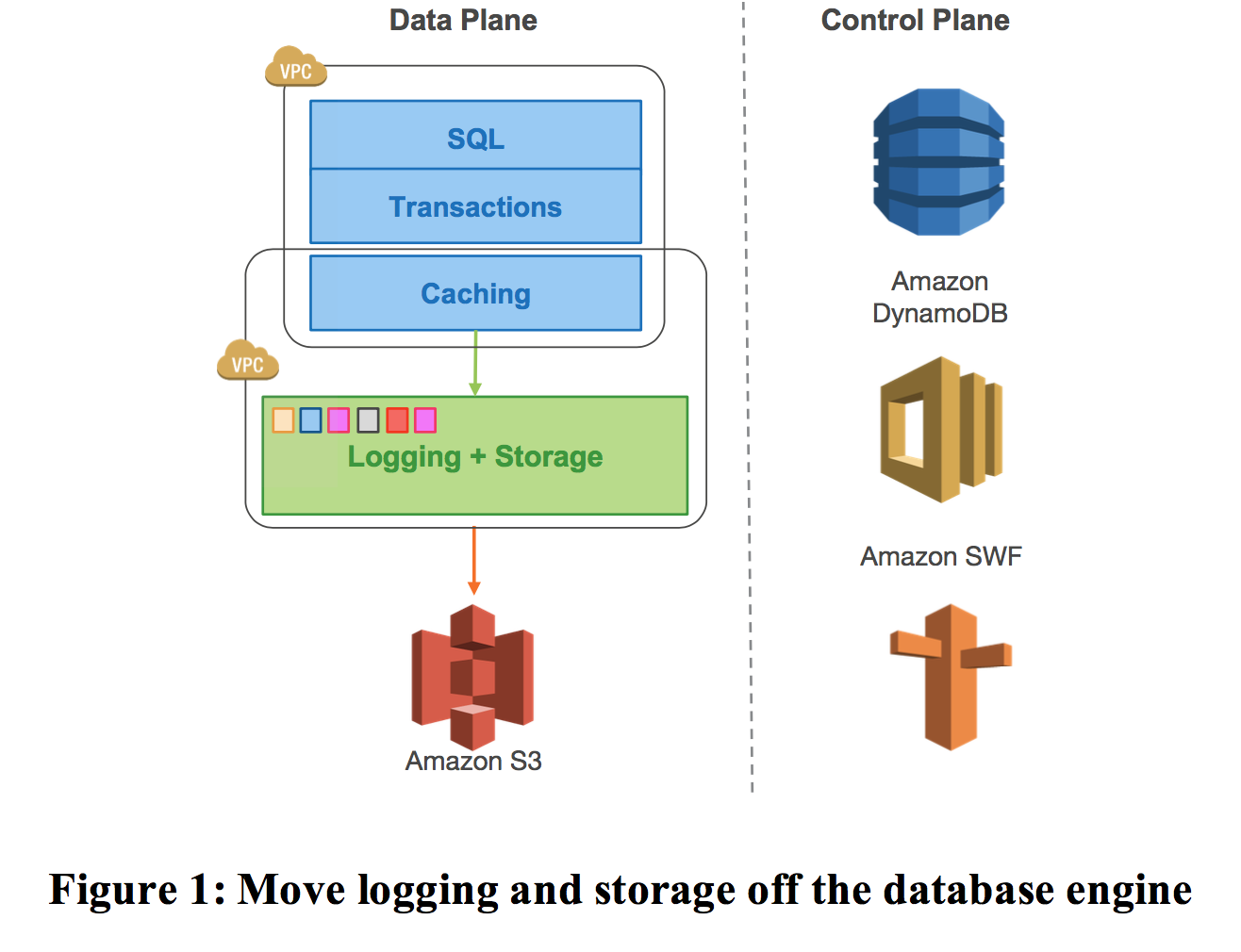
aurora设计是跨3个AZ部署,每个AZ中包括2个副本,相当于是一个6个副本。由于符合一致性约束(V为总副本数,Vr是读副本,Vw是写副本):
- Vr+Vw>V
- Vw>V/2
所以,aurora的设计是,Vw=4,Vr=3。这种设计保证的高可用级别:
- 同时挂掉一整个AZ,以及多余的1个副本,而不影响读。
- 同时挂掉2个副本,不影响写。
存储节点中,数据维护的基本单元是segment,每个segment包含10G的大小,segment在6个副本互相复制中组成1个Protection Group(PG),所以每个PG都有6份10G的segment。Storage Volume是多个PG组装在一起,采用EC2进行本地存储(本地SSD盘)。Volume上限是64TB。segment也是修复的单元,在10G网卡条件下,1个10G的segment能在10s内被修复,这里说的修复也就是重新同步,这也是Aurora的修复方式。这种设计模式不仅可以解决副本挂掉的情况,对于副本延迟大的情况,也可以通过类似心跳的机制进行感知,一旦发现延迟大/OS打patch/软件升级等情况,都可以通过重搭一个副本来解决。
对比一下MySQL的复制模型:
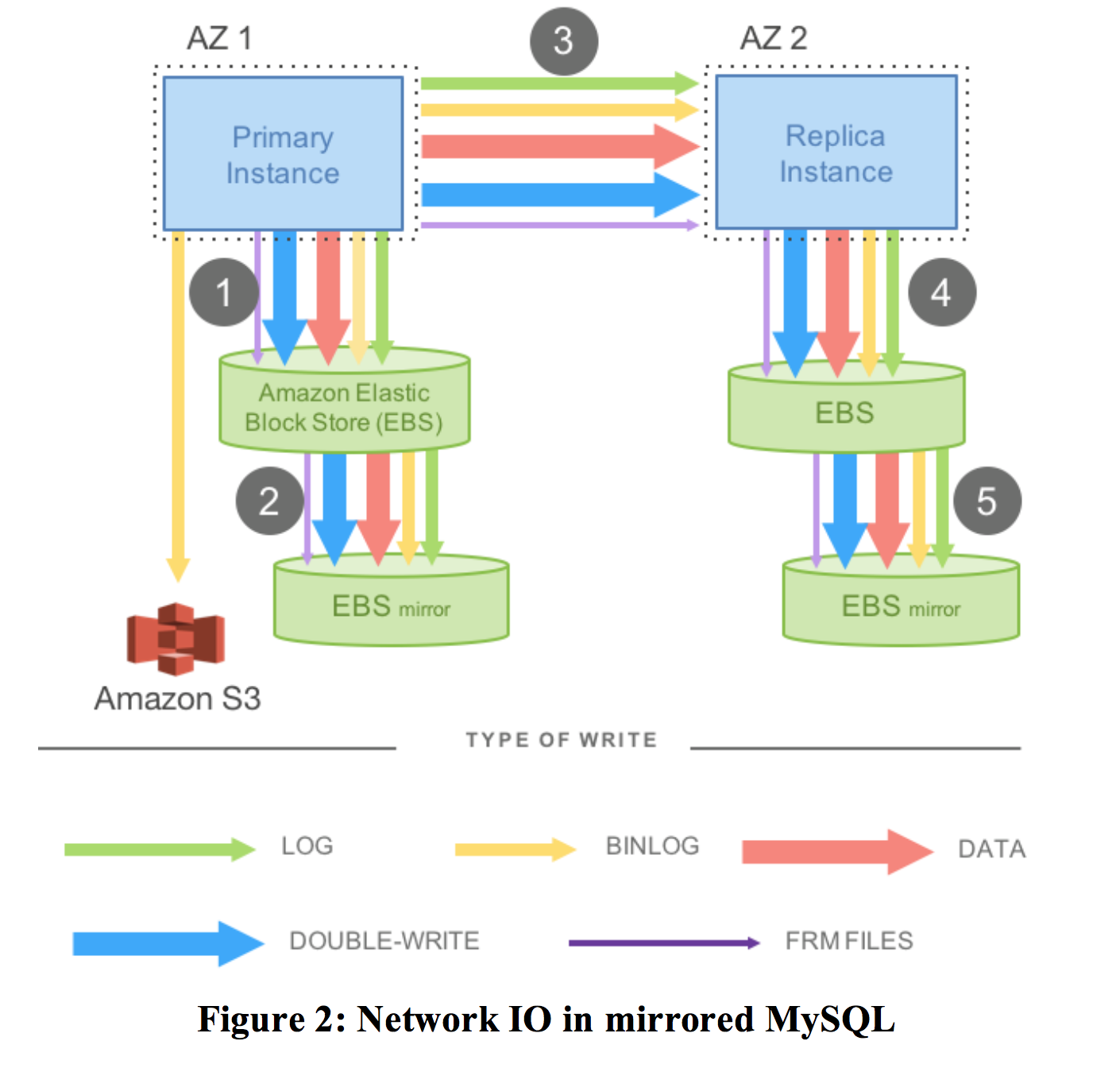
master接受写以后,数据要先写local EBS,等待写成功(WAL+内存提交)回复后,再通过网络同步给slave节点,再经过同样的写。以上这些1,3,4都是同步的操作。这里面EBS盘本身还有多副本,这里可以是一个异步的复制(2,5)。这种方式的缺点是网络延迟大,一旦某一环发生抖动,整体的延迟都会加剧。
Aurora的复制模型:
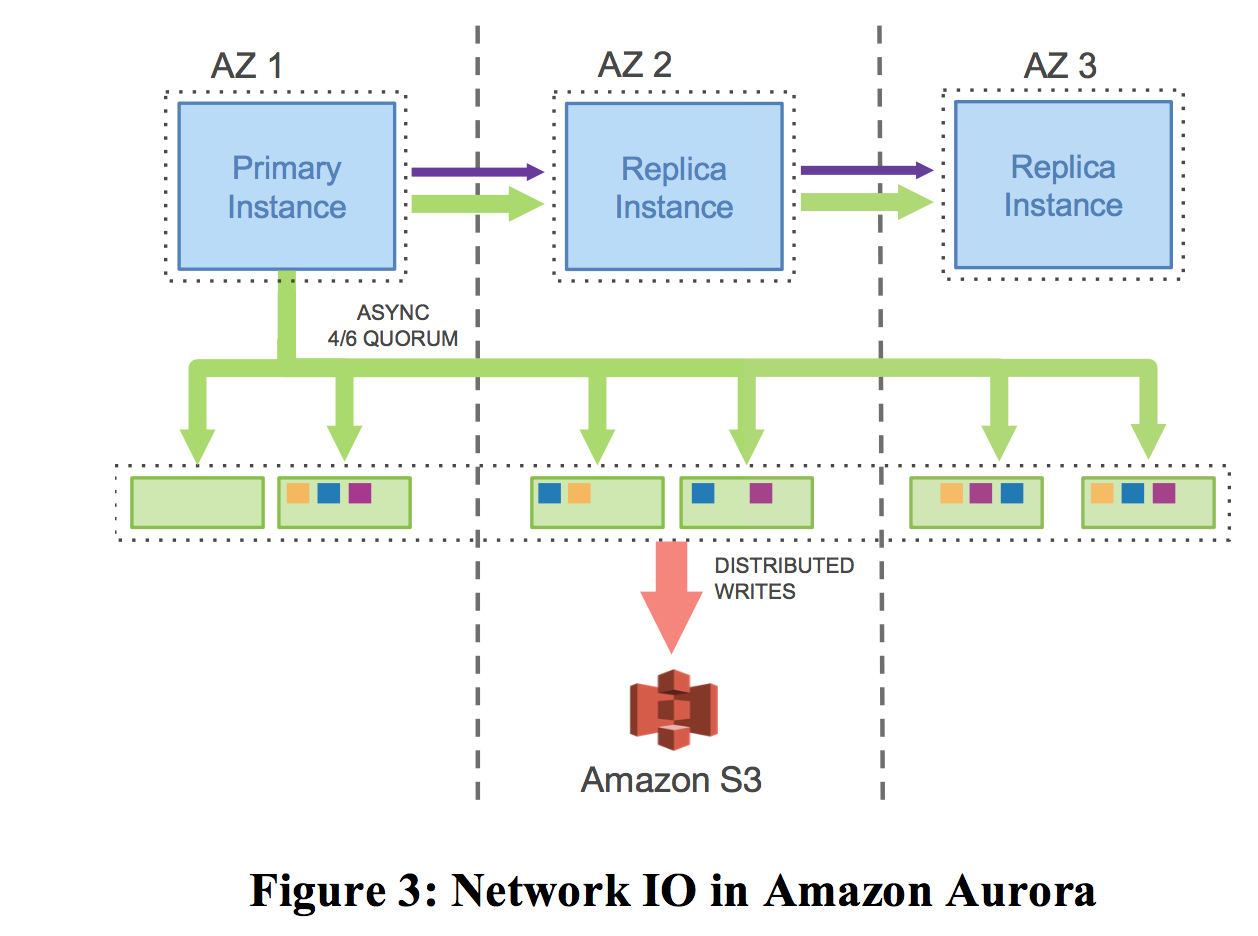
计算节点之间互相同步log+FRM,计算节点写入log到存储节点,写6个副本,等待大多数(4个)副本返回成功再返回上层写成功。这里有2条同步链路:
- 1个是计算节点之间的数据同步,write replica写read replica。这条log和FRM元信息的同步是为了保持read replica的内存是最新的。当然,如果同步过来的log要写的数据本身不存在内存,那么直接丢弃就可以了,下次访问缺页自动会从存储副本中加载最新的。
- 1个是计算节点和存储节点之间的同步。存储节点收到log后本地持久化即认为写成功,然后返回,内存回放,打checkpoint都是异步操作。假设读请求打到了存储节点,发现不是最新的page还没有应用,则会促使存储层log的回放来加载最新的数据。
这种方式总结来说,就是把复制层的数据同步挪到了存储层解决。
关于cache,论文并没有过多的介绍,从论文的脉络能够看出,cache分2层,计算节点和存储节点各有1层cache用于访问的加速。
存储节点之间也会有一定的数据同步:
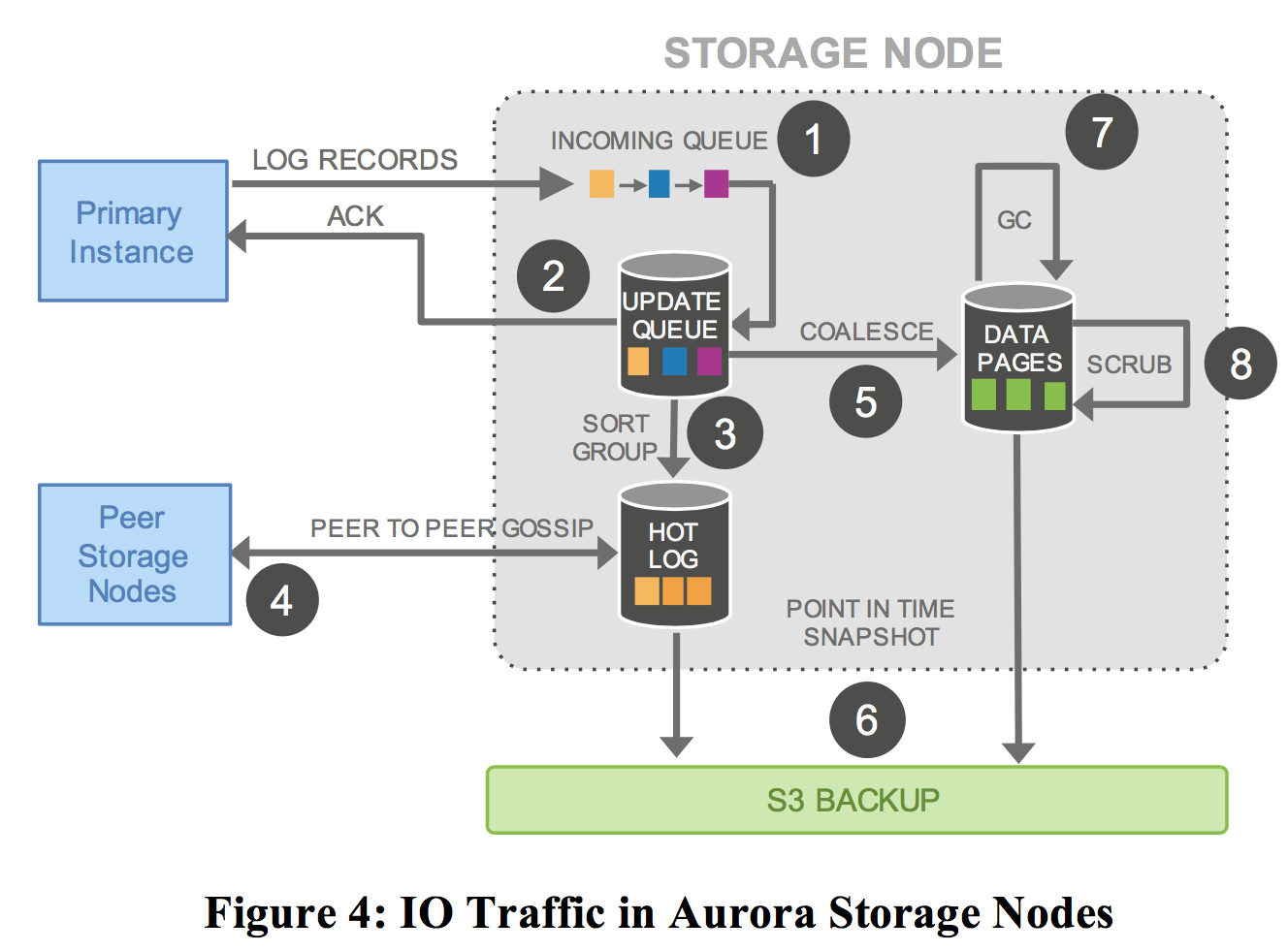
- 存储节点收到计算节点的log,写入内存队列。
- 内存队列持久化成功,就返回ACK给计算节点。
- 从上次同步的位点开始,对数据排序。
- 如果存在丢失的情况,比如异常网络、主机、重启等等,导致数据存在空洞丢失,则通过gossip跟peer node通信,填充空洞数据
- 将log应用到内存B+Tree中。
- 定期将log和B+Tree回写S3。
- 定期做GC清理掉小于一致性位点的数据,我的理解还会做checkpoint。不过具体关于checkpoint的过程,论文中并没有给出过多的说明。
- 定期CRC校验。
上述只有第1,2步是同步的,其余都是异步的。
2. log的复制和转发机制
在节点发生重启,允许访问storage层之间,storage本身会先recovery到一个一致性的状态。VCL是存储节点可用的最大位点(之前数据都写成功了)。CPL是计算节点一致性的位点,VDL是CPL中最大的。最后会根据VDL来恢复出一个一致性的数据,然后truncate掉后面的数据。
对于事务:
- 每一个计算节点的transaction都会被拆成多个mini-transactions(MTRs),单个MTR中保持原子性。多个MTR之间如果保证事务的一致性,包括如何回滚,论文中并没有介绍。
- 每个MTR都是由多个连续的log records组成。
- 每个MTR最后一条log record的LSN号就是CPL。
对于write操作:
- 计算层在收到存储层的write quorum确认后,才会推进VDL。
- 每个操作执行之前都会分配一个有序LSN,LSN本身有一个约束:当前分配的LSN号<当前VDL+LAL(常数)。这个约束是为了保证db层不会一下子分配过多的LSN,导致后端storage节点压力过大。
- 另外由于每个segment都是只有部分数据,所以每个record都有一个反向链接,指向上一条处理的LSN。用于后续在storage节点之间进行gossip传播,找到丢失的log。
对于commit操作:
- 用户线程发起commit以后,db中的线程进行异步提交:标记当前commit LSN位点,然后就去干别的事情了。直到VDL不断推进>=commit LSN以后,db层采用专用线程发生commit ack给用户线程告知提交完成。
对于read操作:
- 只有那些page lsn(当前page写入的最大lsn)大于VDL的page,才会被evict。这个时候表示这个page已经都刷盘了,不是脏页了。这里保留一个问题,假设page都没有大于VDL的,如何淘汰?
- 读的时候因为Vr+Vw>V的,所以肯定能保证读到拥有最新数据的节点。寻找SCL大于read-point的segment返回读。读的时候找到一个Protection Group Min Read Point LSN(PGMRPL),低于这个值的page不会读。
对于replica:
- replicas是只读副本。在一套shared storage volume,用户可以搭建至多15个read replicas提供只读服务。
- 只读reader异步接受writer的log,然后在本地查看是否有对应page在cache中,如果有则更新cache,如果没有则直接丢弃。正常情况下,只读副本落后writer小于20ms。更新的条件如下:1. 只有LSN小于VDL的才会进行更新。why?因为当前读取的一致性快照就是VDL,大于VDL的还没有加载到内存。2. 如果是log record操作的数据位于一个MTR(mini-transaction)中,则回放需要保证原子性。
对于recovery:
- Aurora的Redo log applicator是和database和存储节点的操作是分离的,在后台并行操作。db发生重启后,将会跟存储节点配合执行volume recovery,通常这个恢复时间小于10s。
- 对于内存的状态,会跟PG沟通,读取每个segment的read quorum位点,计算VDL,然后truncate掉后面的。
- 每次truncate都会递增版本号,防止冲突。
- 对于事务的Undo是在recovery之后执行的。
总体架构
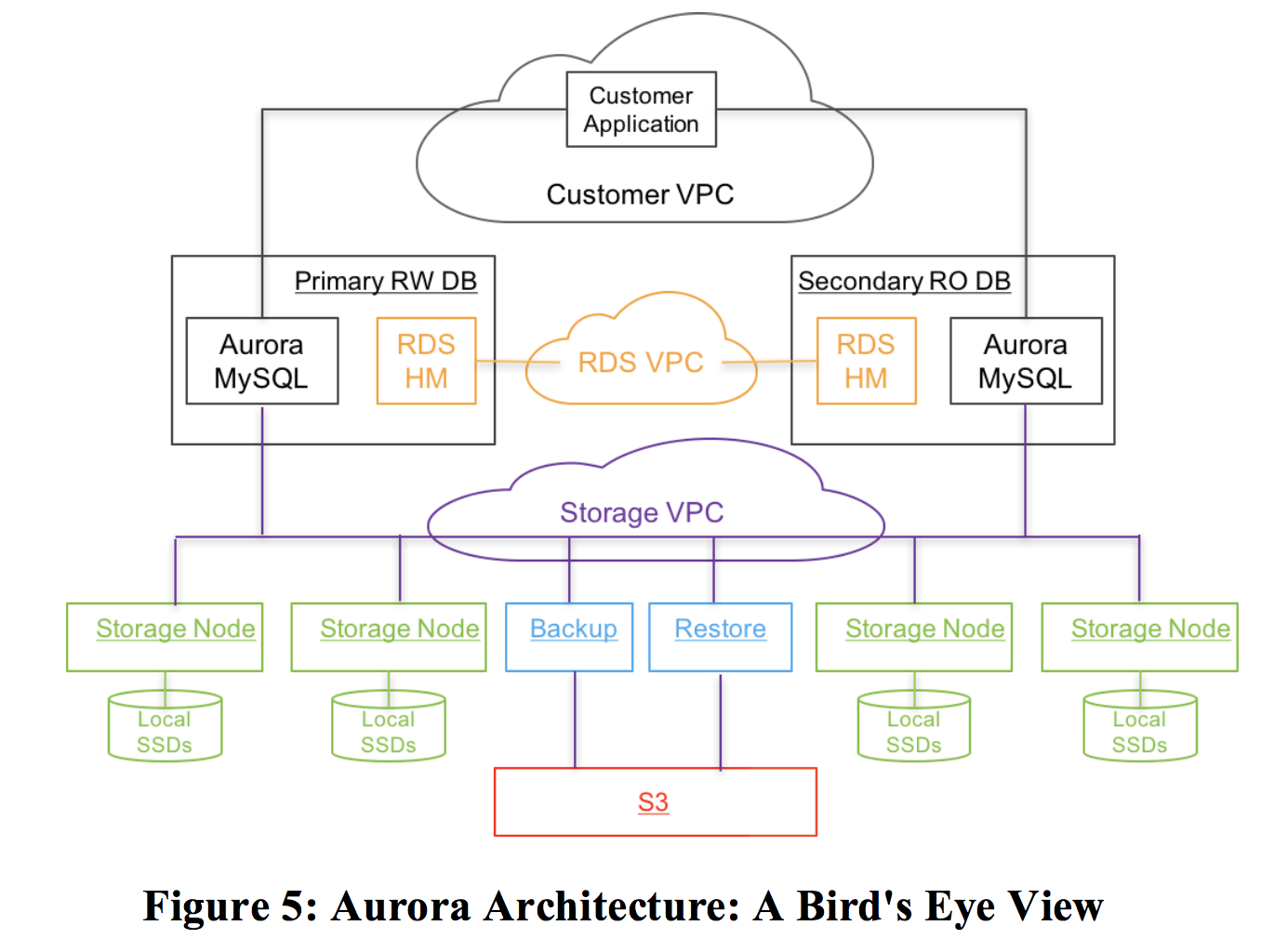
控制平面,aurora采用RDS。RDS包括一个随Aurora部署的Agent(Host Manager,HM),负责健康检查和切换/重搭,一个instance一个agent。一个instance包括1个writer和>=0个read replicas。(所以下面这个图画的优点误导,左边primary RW DB是一个Instance,右边也是一个instance)。一个instance位于一个region,但是通常是放置于不同的AZ(这里说的应该是writer replicas和read replicas)。
出于安全考虑,用户的VPC,RDS的VPC和存储节点的VPC互相隔离。
存储节点部署在EC2上面(类似ECS),本地盘SSD存储。一个region下,跨至少3个AZ。另外,备份和恢复服务是读写S3。关于集群和volume的配置,metadata信息,备份信息,都是放在S3上。
参考:
https://awsmedia.awsstatic-china.com/blog/2017/aurora-design-considerations-paper.pdf